シフト最適化システム OptShift
Shift Optimzation using SCOP (Solver for Constraint Programming)
#hide ### シフト型の最適化モデル(時間帯を考慮しないモデル)
集合:
- \(I\) : スタッフの集合 $= {1,2, , i, |I|} $
- \(J_i\) : スタッフ \(i\) が就くことができるシフトの集合
- \(T\) : 計画日の集合 $= {1,2, , t, |T|} $
パラメータ:
- \(c_{ijt}\) : 日 \(t\) にスタッフ \(i\) がシフト \(j\) に就くときの費用(希望休日出勤の場合には大きくする).
- \(LB_{jt}\) : 日\(t\) のシフト \(j\) で必要なスタッフの人数
- \(p_{jt}\) : 日 \(t\) のシフト \(j\) のスタッフ不足時のペナルティ費用
- \(B_{i}\) : スタッフ \(i\) の勤務日数
変数:
- \(x_{ijt}\) : スタッフ \(i\) が日 \(t\) にシフト \(j\) に就くとき \(1\)、それ以外のとき \(0\) を表す\(0\)-\(1\)変数
SCOPで解く場合は, 変数 \(X_{it}\) を用い,その領域を \(J_i\) とする.
\(y_{it}\): スタッフ \(i\) が日 \(t\) に休むとき \(1\)、それ以外のとき \(0\) を表す\(0\)-\(1\)変数
\(\xi_{jt}\) : 日 \(t\), シフト \(j\) のスタッフ不足数を表す整数変数
定式化:
- 目的関数(スタッフの費用と必要人数逸脱ペナルティの和)
\[ minimize \ \ \sum c_{ijt} x_{ijt} + \sum p_{jt} \xi_{jt} \]
- スタッフがいずれかのシフトに就くか,休むことを表す制約
\[ \sum x_{ijt} + y_{it} = 1 \ \ \ \forall i,t \]
- 連続勤務最大日数 連続勤務は5日まで(6日間の間には必ず1つ休みが入る)
\[ \sum_{s=t}^{t+5} y_{is} \geq 1 \ \ \ \forall i,t \]
- 連休回避 4日連続の休みは回避(連続する4日の中の休みの合計が3以下;ただし希望休は除く)
\[ \sum_{s=t}^{t+3} y_{is} \leq 3 \ \ \ \forall i,t \]
- 必要人数下限制約
\[ \sum_{i: j \in J_i} x_{ijt} +\xi_{jt} \geq LB_{jt} \ \ \ \forall j,t \]
- 勤務日数制約
\[ \sum y_{it} = B_i \ \ \ \forall i \]
- スタッフ1が休みの時はスタッフ2は出勤とする制約
\[ y_{1t} + y_{2t} \leq 1 \ \ \ \forall t \]
- 連続勤務最大日数; 「できるだけ」連続勤務は4日まで(5日間の間には必ず1つ休みが入る)
(破った場合の超過変数を追加し,目的関数にペナルティを入れる;以下同様)
\[ \sum_{s=t}^{t+4} y_{is} \geq 1 \ \ \ \forall i,t \]
- 休,出勤,休みのパターンをできるだけ回避
\[ y_{it} - y_{i,t+1} + y_{i, t+2} \leq 1 \ \ \ \forall i,t \]
- 遅番・早番の連続はできるだけ回避
遅番のシフトの集合を LATE,早番のシフトの集合を EARLYとする.
\[ \sum_{j \in LATE} x_{ijt} + \sum_{j \in EARLY} x_{ij,t+1} \leq 1 \ \ \ \forall i,t \]
#hide
Excel出力
Openpyxlを用いて,結果をExcelファイルに出力する.
シフト最適化
実際問題から生じた以下の仮定の問題を高速に解くための関数群
問題は以下の仮定をもつ.
- 100人程度のスタッフ - 30日程度の計画日 - 30分もしくは1時間単位の計画期(時間帯) - スタッフは作業が可能な業務が与えられている(スキルの設定) - 休憩を入れるためのルール - スタッフのシフト希望 - 日・時間帯・作業ごとの必要人数下限
制約条件を満たす解のうちスタッフの費用の合計を最小化
モデルの定式化
#hide
集合・パラメータ・変数を以下に示す.
集合:
\(I\) : スタッフの集合 $= {1,2, , i, |I|} $
\(J\) : スタッフが就く業務の集合 $= {1,2, , j, |J|} $ ;この中には休憩を表す \(r\) が含まれるものとする。
\(D\) : 計画日の集合 $= {1,2, , d, |D|} $
\(T_{d}\) : 計画日\(d\)における計画期(時間帯;例えば1時間や30分を1単位とする)の集合 $= {0,1, , t, |T_{d}|-1} $
\(T'_{id}\) : スタッフ\(i\)の日\(d\)における勤務可能期の集合 \(= \{t \mid o_{id} \leq t \leq e_{id}, t \in T_{d} \}\) (\(o_{id}\)と\(e_{id}\) はそれぞれ開始可能期と終了期)
\(O_{id}\) : 日 \(d\) にスタッフ\(i\)が、\(\{s \mid o_{id} \leq s < e_{id}-m+1 , s \in T_{d}\}\) 期に勤務を開始し, \(\{t \mid s+m-1 \leq t \leq e_{id} , t \in T_{d}\}\)期に勤務を終了するという組み合わせ\((s, t)\)を要素とした集合 (\(m\) は最低勤務期間数)
\(D_{w}\): 週 \(w\) に含まれる日の集合
\(W\) : 週の集合
パラメータ:
- \(c_{ist}\) : スタッフ\(i\)が\(s\)期に勤務を開始し,\(t\)期に勤務を終了するときの費用
- \(w_{ist}\) : スタッフ\(i\)が\(s\)期に勤務を開始し,\(t\)期に勤務を終了するときの(休憩時間を除いた)稼働期数
- \(LB_{dtj}\) : 日\(d\)の期\(t\)に業務\(j\)で必要なスタッフの人数
- \(h_{dtj}\) : 日\(d\)の期\(t\)における業務\(j\)のスタッフ不足時のペナルティ費用
- \(m\) : 最低勤務期間数.勤務開始から勤務終了まで\(m\)期以上勤務しなければならないものとする。
- \(B_{i}\) : スタッフ\(i\)の計画期間中の勤務日数上限
- \(o_{id}\) : スタッフ\(i\)の日\(d\)における勤務開始可能期
- \(e_{id}\) : スタッフ\(i\)の日\(d\)における勤務終了期限期
- \(\tau_{st}\) : \(s\)期から\(t\)期まで勤務したときに必要な休憩期数
- \(\beta\) : 休憩を開始直後から(もしくは終了直前に)とることを禁止した期数
- \(\zeta_{i}\) : スタッフ\(i\)が勤務業務を変更したときのペナルティ費用
変数:
\(x_{idst}\) : スタッフ\(i\)が日\(d\)期\(s\)に勤務を開始し,期 \(t\) に勤務を終了するとき \(1\)、それ以外のとき \(0\) を表す\(0\)-\(1\)変数
\(y_{idtj}\): スタッフ\(i\)が日\(d\)期\(t\)に業務\(j\)に就くとき \(1\)、それ以外のとき \(0\) を表す\(0\)-\(1\)変数
\(\xi_{dtj}\) : 日\(d\), 期\(t\), 業務\(j\)のスタッフ不足数を表す整数変数
\(u_{idtj}\) : スタッフ\(i\)が日\(d\)期\(t\)に勤務業務を休憩以外の別の勤務業務から\(j\)に変更したとき \(1\)、それ以外のとき \(0\) を表す\(0\)-\(1\)変数
定式化:
\[ \begin{array}{lll} minimize & \sum_{ i \in I} \sum_{ d \in D} \sum_{(s,t) \in O_{id}}c_{ist} x_{idst} + \sum_{ d \in D} \sum_{ t \in T_{d}} \sum_{j \in J} h_{dtj} \xi_{dtj} + \sum_{i \in I} \sum_{d \in D} \sum_{t \in T_{d}} \sum_{j \in J_{i}} \zeta_{i} u_{idtj} & \\ s.t. & \sum_{j \in J_{i}} y_{idkj} = \sum_{(s,t):s \leq k \leq t , (s,t) \in O_{id}} x_{idst} & \forall i \in I, d \in D, k \in T'_{id} \\ & \sum_{(s,t) \in O_{id}} x_{idst} \leq 1 & \forall i \in I, d \in D \\ & \sum_{k \in T'_{id}} y_{idkr} = \sum_{(s,t) \in O_{id}} \tau_{st} x_{idst} & \forall i \in I, d \in D \\ & \sum_{i|j \in J_{i}} y_{idtj} + \xi_{dtj} \geq LB_{dtj} & \forall d \in D, t \in T_{d}, j \in J \\ & \sum_{d \in D} \sum_{(s,t) \in O_{id}} x_{idst} \leq B_{i} & \forall i \in I \\ & y_{idtj} - y_{id,t-1,j} - y_{id,t-1,r} \leq u_{idtj} & \forall i \in I, d \in D, t \in T_{d}, j \in J \\ & \sum^{k+\beta}_{k'=k} y_{idk'r} \leq \beta\left(1 - \sum_{(s,t):s=k ,(s,t) \in O_{id}} x_{idst}\right) & \forall i \in I, d \in D, k \in T'_{d} \\ & \sum^{k}_{k'=k-\beta} y_{idk'r} \leq \beta\left(1 - \sum_{(s,t):t=k ,(s,t) \in O_{id}} x_{idst}\right) & \forall i \in I, d \in D, k \in T'_{d} \\ & \sum_{d \in D_w} \sum_{(s,t) \in O_{id}} w_{ist} x_{idst} \leq 40 & \forall i \in I, w \in W \\ \end{array} \]
目的関数は費用最小化である. - 第1項は、スタッフに支払う賃金を表す. - 第2項は、人員不足時のペナルティ費用を表す. - 第3項は、業務変更の費用を表す。
制約: - 変数\(y_{idtj}\)と変数\(x_{idst}\)の繋がりを表す制約 - 1計画日中に出勤・退勤は高々1度しかないことを表す制約 - 勤務期間内において労働時間に応じた休憩を取らなければならないことを表す制約 - 日\(d\)期\(t\)における業務\(j\)のスタッフの必要人数を満たすことを表す制約 - スタッフ\(i\)の労働期数の上限を表す制約 - 休憩 (添字 \(r\)) 以外からの業務変更を行うときの変数 \(u_{idtj}\) と変数 \(y_{idtj}\) の繋ぎ式 - 勤務開始直後・終了直前における休憩を禁止する制約 - 週あたりの稼働時間が法定の40時間を超えないことを表す制約(未実装)
データ生成
日データ day_df (ファイル名はday.csv)
列: - id : 0から始まる整数 - day : 日付 - day_of_week : 曜日;holidaysパッケージを用いて日本の祝日の場合には Holidayを入れる。 - day_type: 人数の必要量データは、この列の要素ごとに定義される。ここでは、平日 (weekday)、日曜 (sunday)と祝日(holiday)の3種類を準備する。
日データ生成関数 generate_day
引数: - start_date: 開始日を表す文字列 - end_date: 終了日を表す文字列
返値:
day_df: 日データフレーム
generate_day
generate_day (start_date, end_date)
日データ day_df 生成
generate_day関数の使用例
day_df = generate_day('2020-5-1', '2020-5-15')
#day_df.to_csv(folder+"day.csv")
day_df| id | day | day_of_week | day_type | |
|---|---|---|---|---|
| 0 | 0 | 2020-05-01 | Fri | weekday |
| 1 | 1 | 2020-05-02 | Sat | weekday |
| 2 | 2 | 2020-05-03 | Holiday | holiday |
| 3 | 3 | 2020-05-04 | Holiday | holiday |
| 4 | 4 | 2020-05-05 | Holiday | holiday |
| 5 | 5 | 2020-05-06 | Holiday | holiday |
| 6 | 6 | 2020-05-07 | Thu | weekday |
| 7 | 7 | 2020-05-08 | Fri | weekday |
| 8 | 8 | 2020-05-09 | Sat | weekday |
| 9 | 9 | 2020-05-10 | Sun | sunday |
| 10 | 10 | 2020-05-11 | Mon | weekday |
| 11 | 11 | 2020-05-12 | Tue | weekday |
| 12 | 12 | 2020-05-13 | Wed | weekday |
| 13 | 13 | 2020-05-14 | Thu | weekday |
| 14 | 14 | 2020-05-15 | Fri | weekday |
jp_holidays = holidays.Japan()
#dt.date(2015, 1, 1) in jp_holidays
#print(jp_holidays)
day_df = pd.DataFrame(pd.date_range('2020-5-1', '2020-5-15', freq='D'),columns=["day"])
day_df["day_of_week"] = [('Holiday') if t in jp_holidays else (t.strftime('%a')) for t in day_df["day"] ]
n_day = len(day_df)
row_ = []
for row in day_df.itertuples():
if row.day_of_week =="Holiday":
row_.append("holiday")
elif row.day_of_week =="Sun":
row_.append("sunday")
else:
row_.append("weekday")
day_df["day_type"] = row_
day_df["id"] = [t for t in range(len(day_df))]
day_df = day_df.reindex(columns=["id", "day", "day_of_week", "day_type"])
day_df| id | day | day_of_week | day_type | |
|---|---|---|---|---|
| 0 | 0 | 2020-05-01 | Fri | weekday |
| 1 | 1 | 2020-05-02 | Sat | weekday |
| 2 | 2 | 2020-05-03 | Holiday | holiday |
| 3 | 3 | 2020-05-04 | Holiday | holiday |
| 4 | 4 | 2020-05-05 | Holiday | holiday |
| 5 | 5 | 2020-05-06 | Holiday | holiday |
| 6 | 6 | 2020-05-07 | Thu | weekday |
| 7 | 7 | 2020-05-08 | Fri | weekday |
| 8 | 8 | 2020-05-09 | Sat | weekday |
| 9 | 9 | 2020-05-10 | Sun | sunday |
| 10 | 10 | 2020-05-11 | Mon | weekday |
| 11 | 11 | 2020-05-12 | Tue | weekday |
| 12 | 12 | 2020-05-13 | Wed | weekday |
| 13 | 13 | 2020-05-14 | Thu | weekday |
| 14 | 14 | 2020-05-15 | Fri | weekday |
期間データ period_df (ファイル名 period.csv)
1日のスケジュールは、基本時間単位の区間(これを期と呼ぶ)に対して決められる。 以下では、1時間を1期として生成するが、30分や15分でも構わない。 従来のシフトスケジューリングでは、6時間などを1期として扱うことが多かったが、本システムではより細かい時間単位を用いて最適化を行う。 これは、昨今の時間給で働く従業員が増えたことを考慮したものである。
列: - id : 0から始まる整数 - description: 時間区分の説明;期の開始時刻を入れる。例えば、9:00という説明の期は9:00から10:00の区間を表す。
期間データ生成関数 generate_period
引数: - start_time: 開始期の開始時刻 - end_time: 終了期の終了時刻 - freq: 時間の刻みを表す文字列; 1時間(既定値)の場合は”1h”,30分の場合は”30min”と入力する.
返値: period_df: 期間データフレーム
generate_period
generate_period (start_time, end_time, freq='1h')
期間データ生成関数 generate_period
generate_period関数の使用例
9時から21時まで1時間刻みで期データを生成する. 実際には0から11期までの12期分が計画期間になるが,終了時刻を表す21時(12期)が最後に追加されている.これはガントチャートを描画するときに用いるだけである.
#start_time = pd.to_datetime("9:00")
#end_time = pd.to_datetime("21:00")
start_time ="9:00"
end_time = "21:00"
period_df = generate_period(start_time, end_time, freq="1h")
period_df| id | description | |
|---|---|---|
| 0 | 0 | 09:00 |
| 1 | 1 | 10:00 |
| 2 | 2 | 11:00 |
| 3 | 3 | 12:00 |
| 4 | 4 | 13:00 |
| 5 | 5 | 14:00 |
| 6 | 6 | 15:00 |
| 7 | 7 | 16:00 |
| 8 | 8 | 17:00 |
| 9 | 9 | 18:00 |
| 10 | 10 | 19:00 |
| 11 | 11 | 20:00 |
| 12 | 12 | 21:00 |
休憩データ break_df (ファイル名は break.csv)
時間ごとのシフトスケジュールを組む際には、休憩を考慮することも重要になる。 ここでは、就業規則を反映した休憩データを準備するものとする。 これは、1日の稼働時間に対して、何期分の休憩を入れるかを定義したものである。 また、シフトの開始から(もしくは終了前の)何期の間は休憩を入れることができないといった制約も加える。
列: - period : 1日のシフトの稼働時間(最低稼働期間は最初の期;以下の例では3期) - break_time : 休憩を行う期の数
# break.csv
random.seed(1)
T = 13
break_prob = 0.3
period_, break_ = [], []
min_work_time = 3
for t in range(min_work_time, T):
period_.append(t)
if t == min_work_time:
break_ = [0]
else:
if random.random() <= break_prob:
break_.append(break_[-1] + 1)
else:
break_.append(break_[-1])
break_df = pd.DataFrame({"period":period_, "break_time":break_})
#break_df.to_csv(folder + "break.csv")
break_df| period | break_time | |
|---|---|---|
| 0 | 3 | 0 |
| 1 | 4 | 1 |
| 2 | 5 | 1 |
| 3 | 6 | 1 |
| 4 | 7 | 2 |
| 5 | 8 | 2 |
| 6 | 9 | 2 |
| 7 | 10 | 2 |
| 8 | 11 | 2 |
| 9 | 12 | 3 |
休憩時間設定用のExcelファイルを生成する関数 generate_break_excel
引数: - start_time: 開始期の開始時刻 - end_time: 終了期の終了時刻 - freq: 時間の刻みを表す文字列; 1時間(既定値)の場合は”1h”,30分の場合は”30min”と入力する.
返値: wb: ExcelのWorkBookインスタンス
generate_break_excel
generate_break_excel (start_time, end_time, freq)
generate_break_excel関数の使用例
start_time = pd.to_datetime("9:00")
end_time = pd.to_datetime("13:00")
freq="30min"
wb = generate_break_excel(start_time, end_time, freq)
wb.save("break.xlsx")必要人数設定用のExcelファイルを生成する関数 generate_requirement_excel
generate_requirement_excel
generate_requirement_excel (start_time, end_time, freq, job_list)
start_time = pd.to_datetime("9:00")
end_time = pd.to_datetime("13:00")
freq="30min"
job_list= ["レジ打ち", "バックヤード", "接客", "調理"]
wb = generate_requirement_excel(start_time, end_time, freq, job_list)
wb.save("requirement.xlsx")日タイプ情報設定用のExcelファイルを生成する関数 generate_day_excel
generate_day_excel
generate_day_excel (start_date, end_date)
日データ day_df 生成
wb = generate_day_excel('2020-5-1', '2020-5-15')
wb.save("day.xlsx")スタッフ情報設定用のExcelファイルを生成する関数 generate_staff_excel
generate_staff_excel
generate_staff_excel (job_list)
job_list = ["レジ打ち", "バックヤード", "接客", "調理"]
wb = generate_staff_excel(job_list)
wb.save("staff.xlsx")ジョブ(業務)データ job_df (ファイル名は job_csv)
列: - id: : 0から始まる整数 - description : ジョブ(業務、仕事)の名称;最初の行(idは0)には必ず休憩を表す”break”を入れておく。
# job.csv
#description_ = ["break", レジ打ち", "バックヤード", "接客", "調理"]
description_ = ["break", "レジ打ち", "接客"]
n_job = len(description_)
id_ = [t for t in range(n_job)]
job_df = pd.DataFrame({"id":id_, "description":description_})
#job_df.to_csv(folder + "job.csv")
job_df| id | description | |
|---|---|---|
| 0 | 0 | break |
| 1 | 1 | レジ打ち |
| 2 | 2 | 接客 |
スタッフ(従業員)データ staff_df (ファイル名は staff.csv)
列: - name : スタッフの名前 - wage_per_period : 1期あたりの賃金 - max_period : 1日あたりの最大稼働時間 - max_day : 計画期間内に出勤できる最大日数 - job_set : スタッフに割り当てることが可能なジョブ(業務)の集合;ジョブidをリスト形式の文字列で入力する。 - day_off : 出勤できない日のidをリスト形式の文字列で入力する。 - start: 出勤可能な最早期id - end: 退勤する最遅期id
# staff.csv
fake = Faker(['en_US', 'ja_JP','zh_CN','ko_KR'])
Faker.seed(1)
n_day = len(day_df)
n_job = len(job_df)
n_staff = 30
name_ = []
job_list = list(job_df["id"][1:]) #最初のジョブは休憩なので除く
for i in range(n_staff):
name_.append( fake.name() )
staff_df = pd.DataFrame( {"name": name_,
"wage_per_period": np.random.randint(low=850,high=1300,size=n_staff),
"max_period": np.random.randint(5,break_df.period.max()+1, n_staff),
"max_day": np.random.randint(1,3, n_staff),
"job_set": [ str(random.sample(job_list,random.randint(1,n_job-1) )) for s in range(n_staff) ],
"day_off": [ str(random.sample( list(range(n_day)), 1 )) for s in range(n_staff) ],
#"day_off": [ "[]" for s in range(n_staff) ],
"start": np.random.randint(low=0, high=len(period_df)//2 -1, size= n_staff),
"end": np.random.randint(low=len(period_df)//2 + 1, high=len(period_df)-1, size= n_staff)
} )
#staff_df.to_csv(folder+"staff.csv")
staff_df| name | wage_per_period | max_period | max_day | job_set | day_off | start | end | |
|---|---|---|---|---|---|---|---|---|
| 0 | 近藤 裕樹 | 1255 | 7 | 2 | [3, 4] | [11] | 0 | 6 |
| 1 | Jon Cole | 1296 | 8 | 2 | [4] | [9] | 1 | 7 |
| 2 | Rachel Davis | 1121 | 8 | 1 | [4, 3, 1] | [5] | 0 | 7 |
| 3 | 村上 拓真 | 1035 | 7 | 2 | [1] | [7] | 2 | 7 |
| 4 | 김영희 | 1205 | 7 | 2 | [2] | [6] | 0 | 7 |
| 5 | 伊藤 陽子 | 991 | 5 | 1 | [2, 3] | [5] | 2 | 6 |
| 6 | Amanda Johnson | 965 | 6 | 2 | [3, 2] | [6] | 0 | 6 |
| 7 | 심영미 | 924 | 7 | 1 | [3, 2, 4] | [1] | 1 | 7 |
| 8 | 吉田 晃 | 1023 | 8 | 1 | [3] | [1] | 2 | 5 |
| 9 | 徐娟 | 1087 | 5 | 2 | [4, 1] | [14] | 2 | 6 |
| 10 | David Robinson | 927 | 5 | 2 | [3] | [5] | 2 | 6 |
| 11 | 山本 晃 | 1094 | 6 | 1 | [4] | [9] | 1 | 7 |
| 12 | 최은주 | 943 | 5 | 1 | [4] | [7] | 0 | 6 |
| 13 | 中川 陽一 | 1243 | 6 | 2 | [2, 4] | [1] | 1 | 7 |
| 14 | 이정웅 | 1214 | 6 | 1 | [4] | [4] | 2 | 7 |
| 15 | Taylor Henderson | 868 | 7 | 1 | [2] | [3] | 1 | 7 |
| 16 | 장수진 | 1202 | 5 | 1 | [3] | [12] | 2 | 5 |
| 17 | 文雪梅 | 1026 | 6 | 1 | [3, 4, 1] | [9] | 2 | 7 |
| 18 | 최경희 | 1052 | 6 | 2 | [3, 1, 4, 2] | [12] | 2 | 7 |
| 19 | Robert Perry | 1021 | 6 | 1 | [1] | [14] | 0 | 6 |
| 20 | 高畅 | 1101 | 6 | 2 | [4] | [8] | 0 | 5 |
| 21 | 이영희 | 1253 | 8 | 2 | [1] | [13] | 2 | 7 |
| 22 | 石玲 | 1162 | 5 | 1 | [2, 3] | [11] | 0 | 7 |
| 23 | John Johnson | 898 | 6 | 1 | [2, 1, 4, 3] | [7] | 2 | 6 |
| 24 | 橋本 零 | 962 | 7 | 1 | [2, 3] | [10] | 2 | 7 |
| 25 | 加藤 加奈 | 985 | 5 | 1 | [4] | [5] | 0 | 7 |
| 26 | 鞠秀荣 | 1166 | 6 | 1 | [3, 4, 2, 1] | [4] | 2 | 6 |
| 27 | 石井 くみ子 | 1037 | 7 | 2 | [1, 4, 2] | [2] | 2 | 6 |
| 28 | 解英 | 1091 | 6 | 2 | [1] | [8] | 0 | 7 |
| 29 | 이영철 | 1087 | 7 | 2 | [3] | [3] | 0 | 7 |
必要人数データ requirement_df (ファイル名は requirement.csv)
列: - day_type : day_dfの day_type列で入力した日の種類;この種類別に必要人数を定義する。 - job : ジョブid - period : 期id - requirement : 必要人数
# requirement
n_period = len(period_df)-1
day_type = ["weekday", "sunday", "holiday"]
type_, job_, period_, lb_ = [],[],[],[]
for d in day_type:
for j in range(1,n_job): #ジョブ番号0は休憩なので除く
req_ = np.ones(n_period, int)
lb = 0
ub = n_period
for iter_ in range(4):
lb = lb + random.randint(1, 3)
ub = ub - random.randint(1, 3)
if lb < ub:
for t in range(lb,ub):
req_[t]+=1
for t in range(n_period):
type_.append(d)
job_.append(j)
period_.append(t)
lb_.append(req_[t])
requirement_df = pd.DataFrame({"day_type":type_, "job":job_, "period":period_,"requirement":lb_ })
#requirement_df.to_csv(folder+"requirement.csv")
requirement_df.head()| day_type | job | period | requirement | |
|---|---|---|---|---|
| 0 | weekday | 1 | 0 | 1 |
| 1 | weekday | 1 | 1 | 1 |
| 2 | weekday | 1 | 2 | 1 |
| 3 | weekday | 1 | 3 | 2 |
| 4 | weekday | 1 | 4 | 3 |
JSONデータをデータフレームに変換する関数 convert_shift_data
Streamlitでfirebaseのデータベースから得たJSON形式のデータを最適化関数の入力となるデータフレームに変換する.
引数: - day_json : 日JSONデータ - break_df : 休憩JSONデータ - staff_df : スタッフJSONデータ - requirement_df : 必要人数JSONデータ - min_work_periods: 最小稼働期間(既定値は1)
返値: - period_df : 期間データフレーム - break_df : 休憩データフレーム - day_df : 日データフレーム - job_df : ジョブデータフレーム - staff_df : スタッフデータフレーム - requirement_df : 必要人数データフレーム
# with open("staff.json") as f:
# staff_json = f.read()
# staff_data = pd.read_json(staff_json)
# staff_df = staff_data[ ["ニックネーム", "優先度", "最大稼働期間", "最大出勤日数", "開始時刻", "終了時刻", "日別希望時間"] ]
# #dic = staff_df.日別希望時間[1]
# day_dic ={d:t for d,t in zip(day_df.day, day_df.index)}
# period_dic = {d:i for d,i in zip(period_df.description, period_df.id) }
# request = []
# for req in staff_df.日別希望時間:
# if req is None or len(req)==0:
# request.append(None)
# continue
# D ={}
# for key in req:
# try:
# D[ day_dic[key] ] = (period_dic.get(req[key][0],0), period_dic.get(req[key][0],period_df.id.max()-1) )
# except KeyError: #対応する日が計画期間内にない
# pass
# if len(D)>=1:
# request.append(str(D))
# else:
# request.append(None)convert_shift_data
convert_shift_data (day_json, break_json, staff_json, requirement_json, min_work_periods=1)
convert_shift_data関数の使用例
# day_df = pd.read_excel("day.xlsx") #id, day, day_of_week, day_type
# break_df = pd.read_excel("break.xlsx") #id,description
# staff_data = pd.read_csv("staff.csv") #name (=nickname), wage_per_period (=priority), max_period, max_day, job_set, day_off, start, end
# requirement_dic = pd.read_excel("requirement.xlsx", sheet_name = None, header=1)
# import json
# with open("day.json") as f:
# day_json = f.read()
# with open("break.json") as f:
# break_json = f.read()
# with open("staff.json") as f:
# staff_json = f.read()
# with open("requirement.json") as f:
# requirement_json = f.read()
# period_df, break_df, day_df, job_df, staff_df, requirement_df = convert_shift_data(day_json, break_json,
# staff_json, requirement_json, min_work_periods = 3)
# cost_df, violate_df, new_staff_df, job_assign, status = shift_scheduling(period_df, break_df, day_df, job_df, staff_df, requirement_df, theta=1,
# lb_penalty =10000, ub_penalty =10000, job_change_penalty = 10, break_penalty = 10000, max_day_penalty = 5000,
# OutputFlag=False, TimeLimit=1, random_seed = 2)アナリティクス
スタッフの情報と必要人数データから,大まかな実行可能性を調べる.
スタッフが確率的にジョブや時間に割り当てられたと仮定して,必要量との比率を求め,可視化する.
# n_day = len(day_df)
# n_job = len(job_df)
# n_period = len(period_df)-1
# work_hours = np.zeros( (n_job,n_day,n_period) )
# for row in staff_df.itertuples():
# job_set = ast.literal_eval(row.job_set)
# day_off = set( ast.literal_eval(row.day_off) )
# max_period = row.max_period #最大稼働時間/1日の稼働時間 だけ加算する
# max_day = row.max_day #最大稼働日数/計画期間 だけ加算する.
# ratio = max_period/n_period * max_day/n_day
# #print(ratio)
# for d in range(n_day):
# if d not in day_off:
# for j in job_set:
# for t in range(row.start, row.end+1):
# work_hours[j,d,t]+= ratio
# work_hours[1]# requirement ={}
# for row in requirement_df.itertuples():
# requirement[row.day_type, row.period, row.job] = row.requirement
# req = np.zeros( (n_job, n_day, n_period) )
# for d, row in enumerate(day_df.itertuples()):
# for j in range(1,n_job):
# for t in range(n_period):
# req[j,d,t] += requirement[row.day_type,t,j]# import seaborn as sns
# sns.heatmap(work_hours[1]/req[1], annot=True, fmt="1.2f");# fig = px.imshow(work_hours[1]/req[1], color_continuous_scale=px.colors.sequential.Viridis)
# fig.update_xaxes(side="top")
# plotly.offline.plot(fig);スタッフの希望と必要人数の関係を調べる関数 estimate_requirement
estimate_requirement
estimate_requirement (day_df, period_df, job_df, staff_df, requirement_df, days=None)
#fig = estimate_requirement(day_df, period_df, job_df, staff_df, requirement_df, days=[1,2,3])
#plotly.offline.plot(fig);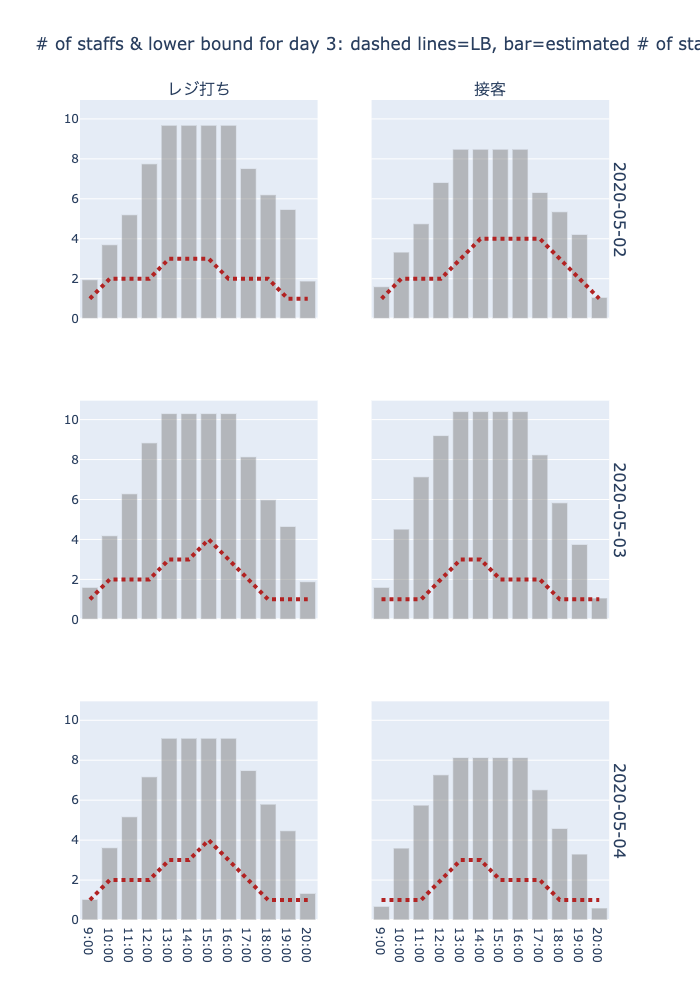
制約逸脱計算関数 evaluate_violation
引数: - violated (最適化で得られた逸脱量を表す辞書)
返値: - cost_df: 逸脱ペナルティを入れたデータフレーム
evaluate_violation
evaluate_violation (violated, x, period_df, day_df, staff_df)
制約逸脱計算関数
evaluate_violation関数の使用例
shift_schedulingの中で使用する.
SCOP Model
制約最適化ソルバー SCOP を用いたモデルを記述する。
引数:
- period_df : 期間データフレーム
- break_df : 休憩データフレーム
- day_df : 日データフレーム
- job_df : ジョブデータフレーム
- staff_df : スタッフデータフレーム
- requirement_df : 必要人数データフレーム
- theta : 開始直後(もしくは終了直前)に休憩を禁止する期間数(既定値は1)
- lb_penalty : 必要人数を下回った場合のペナルティ(既定値は10000)
- ub_penalty : 必要人数を上回った場合のペナルティ(既定値は0)
- job_change_penalty : ジョブを切り替えたときのペナルティ(既定値は10)
- break_penalty : 開始直後・終了直前の休憩を逸脱したときのペナルティ(既定値は10000)
- max_day_penalty : 最大稼働日数を超過したときのペナルティ(既定値は5000)
- OutputFlag : 出力フラグ;ソルバーの出力を出す場合にはTrue (既定値はFalse)
- TimeLimit : 計算時間上限(既定値は10秒)
- random_seed : ソルバーで用いる擬似乱数の種(既定値は1)
- cloud: 複数人が同時実行する可能性があるときTrue(既定値はFalse); Trueのとき,ソルバー呼び出し時に生成されるファイルにタイムスタンプを追加し,計算終了後にファイルを消去する.
返値: - x : 変数 \(x\) を入れた辞書 - y : 変数 \(y\) を入れた辞書 - sol : 解を表す辞書 - violated : 逸脱した制約を表す辞書 - new_staff_df : スタッフデータフレームにシフトを追加したもの - job_assign: スタッフに割り当てられたジョブの情報を保持した辞書 - status : 最適化の状態を表す数字;以下の意味を持つ。
| status | 意味 |
|---|---|
| 0 | 最適化成功 |
| 1 | 求解中にユーザが Ctrl-C を入力したことによって強制終了した. |
| 2 | 入力データファイルの読み込みに失敗した. |
| 3 | 初期解ファイルの読み込みに失敗した. |
| 4 | ログファイルの書き込みに失敗した. |
| 5 | 入力データの書式にエラーがある. |
| 6 | メモリの確保に失敗した. |
| 7 | 実行ファイル scop.exe のよび出しに失敗した. |
| 10 | モデルの入力は完了しているが,まだ最適化されていない. |
| 負の値 | その他のエラー |
shift_scheduling
shift_scheduling (period_df, break_df, day_df, job_df, staff_df, requirement_df, theta=1, lb_penalty=10000, ub_penalty=0, job_change_penalty=10, break_penalty=10000, max_day_penalty=5000, OutputFlag=False, TimeLimit=10, random_seed=1, cloud=False)
シフト最適化
SCOP(日別リクエスト)モデル
staff_dfに request列を追加
希望日をキー,開始,終了時刻を値
shift_scheduling2
shift_scheduling2 (period_df, break_df, day_df, job_df, staff_df, requirement_df, theta=1, lb_penalty=10000, ub_penalty=0, job_change_penalty=10, break_penalty=10000, max_day_penalty=5000, OutputFlag=False, TimeLimit=10, random_seed=1, cloud=False)
シフト最適化(スタッフが日毎に開始希望時刻と終了希望時刻を入れられるように変更)
# cost_df, violate_df, new_staff_df, job_assign, status = shift_scheduling2(period_df, break_df, day_df, job_df, staff_df, requirement_df, theta=1,
# lb_penalty =10000, ub_penalty =10000, job_change_penalty = 10, break_penalty = 10000, max_day_penalty = 5000,
# OutputFlag=False, TimeLimit=30, random_seed = 2)# cost_dfshift_scheduling関数の使用例
# period_df = pd.read_csv(folder+"period.csv", index_col=0)
# break_df = pd.read_csv(folder+"break.csv", index_col=0)
# day_df = pd.read_csv(folder+"day.csv", index_col=0)
# job_df = pd.read_csv(folder+"job.csv", index_col=0)
# staff_df = pd.read_csv(folder+"staff.csv", index_col=0)
# requirement_df = pd.read_csv(folder+"requirement.csv", index_col=0)
# cost_df, violate_df, new_staff_df, job_assign, status = shift_scheduling(period_df, break_df, day_df, job_df, staff_df, requirement_df, theta=1,
# lb_penalty =10000, ub_penalty =10000, job_change_penalty = 10, break_penalty = 10000, max_day_penalty = 5000,
# OutputFlag=False, TimeLimit=30, random_seed = 2)# cost_df# violate_df#job_assign#new_staff_df| name | wage_per_period | max_period | max_day | job_set | day_off | start | end | Shift for Day 0 | Shift for Day 1 | Shift for Day 2 | Shift for Day 3 | Shift for Day 4 | max day violation | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Ryan Gallagher | 908 | 10 | 13 | [2] | [1] | 2 | 7 | None | None | None | None | 3_7 | 0.0 |
| 1 | 박영길 | 1284 | 11 | 10 | [2, 1] | [4] | 2 | 7 | None | None | None | None | None | 0.0 |
| 2 | Rachel Davis | 1226 | 9 | 12 | [2, 1] | [2] | 3 | 8 | None | None | None | None | None | 0.0 |
| 3 | 史建平 | 1124 | 8 | 10 | [2, 1] | [2] | 3 | 10 | 7_9 | 4_6 | None | 5_10 | None | 0.0 |
| 4 | 김영희 | 972 | 12 | 10 | [2, 1] | [1] | 4 | 8 | 4_6 | None | None | 4_6 | 4_6 | 0.0 |
| 5 | 김현정 | 936 | 9 | 13 | [1] | [3] | 2 | 9 | None | 2_7 | 3_5 | None | 5_7 | 0.0 |
| 6 | 王洋 | 1123 | 10 | 12 | [1] | [1] | 3 | 9 | None | None | 6_8 | None | None | 0.0 |
| 7 | Teresa James | 1017 | 9 | 11 | [1] | [1] | 0 | 9 | 5_7 | None | 3_7 | 0_4 | 0_2 | 0.0 |
| 8 | Javier Johnson | 960 | 9 | 13 | [1] | [2] | 4 | 9 | None | 6_9 | None | 6_8 | 6_8 | 0.0 |
| 9 | Jeffrey Simpson | 911 | 8 | 10 | [1, 2] | [1] | 4 | 9 | 4_9 | None | None | 5_7 | None | 0.0 |
| 10 | David Robinson | 1021 | 11 | 13 | [2] | [3] | 1 | 8 | 5_7 | 1_3 | 3_5 | None | None | 0.0 |
| 11 | 이경수 | 1026 | 8 | 10 | [1] | [4] | 4 | 11 | None | 4_6 | 4_6 | 4_6 | None | 0.0 |
| 12 | 罗玉英 | 1220 | 12 | 12 | [2] | [4] | 3 | 9 | None | None | None | None | None | 0.0 |
| 13 | 진준호 | 1194 | 8 | 14 | [1] | [0] | 0 | 11 | None | None | 0_2 | None | None | 0.0 |
| 14 | 杨洁 | 1201 | 10 | 14 | [2, 1] | [4] | 1 | 8 | 4_6 | 5_7 | 5_7 | 3_5 | None | 0.0 |
| 15 | 谷红霞 | 1183 | 9 | 14 | [2] | [4] | 0 | 10 | 4_6 | None | 0_2 | 2_4 | None | 0.0 |
| 16 | 장수진 | 1287 | 10 | 13 | [2] | [4] | 3 | 11 | 8_10 | 7_9 | 7_11 | None | None | 0.0 |
| 17 | 文雪梅 | 1142 | 9 | 10 | [1, 2] | [1] | 0 | 10 | 1_3 | None | None | None | None | 0.0 |
| 18 | 최경희 | 943 | 11 | 14 | [1] | [3] | 4 | 11 | 8_11 | 8_11 | 8_10 | None | 7_11 | 0.0 |
| 19 | 안승현 | 1168 | 10 | 10 | [2] | [2] | 2 | 7 | 2_4 | 4_6 | None | None | None | 0.0 |
| 20 | Joshua Warner | 1237 | 8 | 11 | [2] | [2] | 2 | 11 | 6_9 | 6_11 | None | None | None | 0.0 |
| 21 | 이영희 | 1121 | 9 | 14 | [2, 1] | [3] | 2 | 10 | None | 5_7 | 4_6 | None | 3_5 | 0.0 |
| 22 | 石玲 | 993 | 11 | 12 | [2] | [2] | 0 | 11 | 0_2 | 0_2 | None | 0_4 | 0_3 | 0.0 |
| 23 | 杉山 晃 | 1199 | 8 | 13 | [1] | [2] | 0 | 11 | 1_3 | None | None | 7_11 | 1_6 | 0.0 |
| 24 | 한현준 | 1243 | 11 | 11 | [1, 2] | [3] | 0 | 10 | 7_9 | 7_9 | None | None | 5_10 | 0.0 |
| 25 | 佐々木 加奈 | 1063 | 12 | 13 | [2, 1] | [1] | 4 | 11 | 7_11 | None | None | 7_11 | 4_6 | 0.0 |
| 26 | Vicki Townsend | 985 | 8 | 13 | [1, 2] | [3] | 3 | 7 | None | 3_7 | None | None | None | 0.0 |
| 27 | 山岸 くみ子 | 1144 | 10 | 14 | [1, 2] | [2] | 0 | 11 | 0_5 | 0_3 | None | 1_3 | 8_11 | 0.0 |
| 28 | 解英 | 1056 | 10 | 10 | [2, 1] | [4] | 2 | 11 | None | 8_10 | 6_11 | 5_7 | None | 0.0 |
| 29 | 陈萍 | 1015 | 11 | 12 | [2, 1] | [3] | 1 | 9 | None | 1_4 | 1_6 | None | 2_4 | 0.0 |
#fig = make_requirement_graph(day_df, period_df, job_df, staff_df, requirement_df, job_assign, day=1)
#plotly.offline.plot(fig);#fig = make_gannt_for_shift(day_df, period_df, staff_df, job_df, job_assign, day=1 )
#plotly.offline.plot(fig);Excel出力
日ごとのジョブのガントチャートのExcel Workbookを生成する関数 make_gannt_excel
引数: - job_assign: スタッフに割り当てられたジョブの情報を保持した辞書 - period_df : 期間データフレーム - day_df : 日データフレーム - job_df : ジョブデータフレーム - staff_df : スタッフデータフレーム - requirement_df : 必要人数データフレーム
返値: wb: Excel (OptnPyXL) のWorkBookオブジェクト
make_gannt_excel
make_gannt_excel (job_assign, period_df, day_df, job_df, staff_df, requirement_df)
make_gannt_excel関数の使用例
# wb = make_gannt_excel(job_assign, period_df, day_df, job_df, staff_df, requirement_df)
# wb.save("shift_gannt.xlsx")期間内のシフト一覧を出力する関数 make_allshift_excel
引数: - new_staff_df : スタッフデータフレーム(シフトを追加したもの) - day_df : 日データフレーム
返値: wb: Excel (OptnPyXL) のWorkBookオブジェクト
make_allshift_excel
make_allshift_excel (new_staff_df, day_df, period_df)
make_allshift_excel関数の使用例
# wb = make_allshift_excel(new_staff_df, day_df, period_df)
# wb.save("all_shift.xlsx")# pd.read_excel("all_shift.xlsx")可視化
必要人数を描画する関数 make_requirement_graph
引数: - day_df : 日データフレーム - period_df : 期間データフレーム - job_df : ジョブデータフレーム - staff_df : スタッフデータフレーム - requirement_df : 必要人数データフレーム - job_assign : 変数 \(y\) の情報(スタッフiが日dの期tに割り当てられたジョブの番号)を入れた辞書(キーは文字列) - day : 描画したい日のid
返値: - fig : Plotlyのグラフオブジェクト
make_requirement_graph
make_requirement_graph (day_df, period_df, job_df, staff_df, requirement_df, job_assign, day=0)
必要人数のグラフを生成する関数
make_requirement_graphの使用例
# print("Status",status)
# if status ==0: #SCOPが失敗していないときのみ表示
# fig = make_requirement_graph(day_df, period_df, job_df, staff_df, requirement_df, job_assign, day = 0)
# plotly.offline.plot(fig);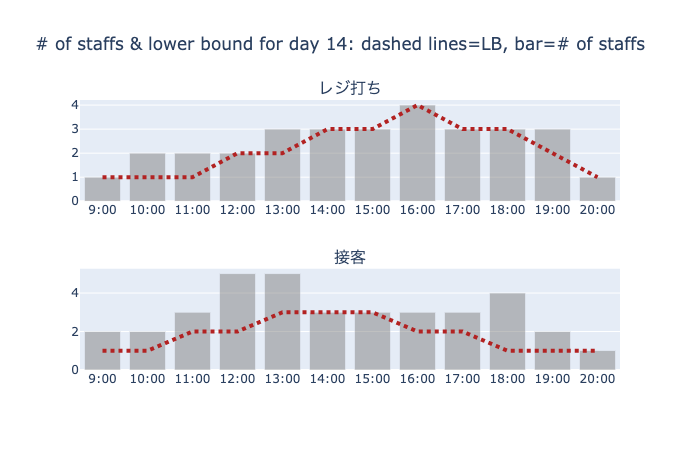
ガントチャートを描画する関数 make_gannt_for_shift
引数: - day_df : 日データフレーム - period_df : 期間データフレーム - staff_df : スタッフデータフレーム - job_df : ジョブデータフレーム - requirement_df : 必要人数データフレーム - job_assign : 変数 \(y\) の情報(スタッフiが日dの期tに割り当てられたジョブの番号)を入れた辞書(キーは文字列) - day_off : 希望休日を入れた辞書 - day : 描画したい日のid
返値: - fig : Plotlyのグラフオブジェクト
make_gannt_for_shift
make_gannt_for_shift (day_df, period_df, staff_df, job_df, job_assign, day=0)
スタッフごとのガントチャートを生成する関数
make_gannt_for_shiftの使用例
# if status ==0: #SCOPが失敗していないときのみ表示
# fig = make_gannt_for_shift(day_df, period_df, staff_df, job_df, job_assign, day=0 )
# plotly.offline.plot(fig);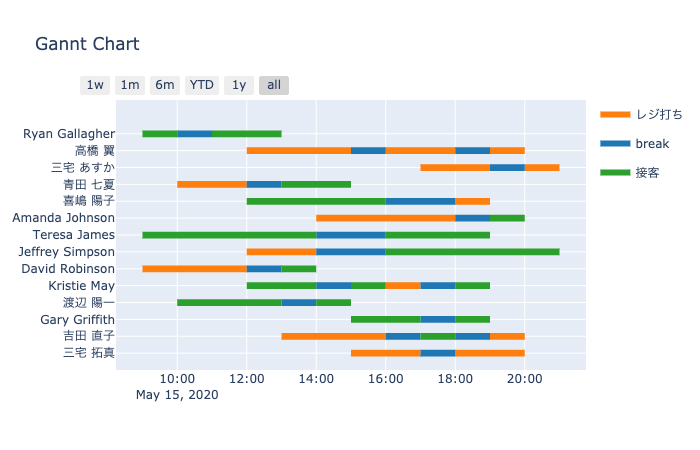
計算の過程を表示する関数 lot_scop_for_shift
引数:
- file_name: SCOPの出力ファイル名;既定値は “scop_out.txt”
返値: - Plotlyの図オブジェクト
plot_scop_for_shift
plot_scop_for_shift (file_name:str='scop_out.txt')
plot_scop_for_shift関数の使用例
# fig = plot_scop_for_shift("scop_out.txt")
# plotly.offline.plot(fig);