prod_df = pd.read_csv(folder+"prod.csv",index_col=0)
prod_df.head()| name | weight | volume | cust_value | dc_value | plnt_value | fixed_cost | |
|---|---|---|---|---|---|---|---|
| 0 | A | 2 | 0 | 7 | 1 | 1 | 14 |
| 1 | B | 5 | 0 | 5 | 1 | 1 | 14 |
| 2 | C | 1 | 0 | 5 | 1 | 1 | 19 |
| 3 | D | 3 | 0 | 5 | 1 | 1 | 17 |
| 4 | E | 1 | 0 | 10 | 1 | 1 | 18 |
サプライ・チェイン・アナリティクスで最初に行うことは、需要データに対するABC分析である。 商品の需要量というのは、売れるものはたくさん売れるが、その数はごく少数であり、他のたくさんのそんなに売れない商品が山ほどあるという性質を持つ。 これをパレートの法則(全体の数値の大部分は、全体を構成するうちの一部の要素が生み出しているという理論。別名、80:20の法則、もう1つの別名、ばらつきの法則)と呼ぶ。
ここでは、仮想の企業の需要を生成し、それに対してABC分析を行う。 同時に、商品を売れている順に順位をつけ、順位の時系列的な変化を示すランク分析を提案する。
さらに、簡単な在庫分析を行う。これは、平均需要量や生産固定費用から、生産ロットサイズや安全在庫量を計算するものであり、 古典的な経済発注量モデルや安全在庫モデル(新聞売り子モデル)に基づくものである。
まずは基本となるデータを読み込む。製品データはオプションであり、需要を売り上げや需要を重量や容量で評価したい場合に使う。 基本は、需要データ demand_df だけを使えば十分である。
需要データは以下の列をもつ.
需要量demandと売上の何れかに対して,ABC分析を行う.
prod_df = pd.read_csv(folder+"prod.csv",index_col=0)
prod_df.head()| name | weight | volume | cust_value | dc_value | plnt_value | fixed_cost | |
|---|---|---|---|---|---|---|---|
| 0 | A | 2 | 0 | 7 | 1 | 1 | 14 |
| 1 | B | 5 | 0 | 5 | 1 | 1 | 14 |
| 2 | C | 1 | 0 | 5 | 1 | 1 | 19 |
| 3 | D | 3 | 0 | 5 | 1 | 1 | 17 |
| 4 | E | 1 | 0 | 10 | 1 | 1 | 18 |
demand_df = pd.read_csv(folder+"demand_with_promo_all.csv",index_col=0)
demand_df.head()| date | cust | prod | promo_0 | promo_1 | demand | |
|---|---|---|---|---|---|---|
| 0 | 2019-01-01 | 札幌市 | A | 0 | 0 | 6 |
| 1 | 2019-01-01 | 札幌市 | B | 0 | 0 | 6 |
| 2 | 2019-01-01 | 札幌市 | C | 0 | 0 | 6 |
| 3 | 2019-01-01 | 札幌市 | D | 0 | 0 | 5 |
| 4 | 2019-01-01 | 札幌市 | E | 0 | 0 | 11 |
以下で配布されているデータを読み込む.
https://www.kaggle.com/kyanyoga/sample-sales-data
Kaggleデータを用いたい場合には,以下を実行する. ただし,製品データがないので,製品関連の関数は適用できない.
kaggle_df = pd.read_csv(folder + "sales_data_sample.csv", encoding="latin")
kaggle_df.head()| ORDERNUMBER | QUANTITYORDERED | PRICEEACH | ORDERLINENUMBER | SALES | ORDERDATE | STATUS | QTR_ID | MONTH_ID | YEAR_ID | ... | ADDRESSLINE1 | ADDRESSLINE2 | CITY | STATE | POSTALCODE | COUNTRY | TERRITORY | CONTACTLASTNAME | CONTACTFIRSTNAME | DEALSIZE | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 10107 | 30 | 95.70 | 2 | 2871.00 | 2/24/2003 0:00 | Shipped | 1 | 2 | 2003 | ... | 897 Long Airport Avenue | NaN | NYC | NY | 10022 | USA | NaN | Yu | Kwai | Small |
| 1 | 10121 | 34 | 81.35 | 5 | 2765.90 | 5/7/2003 0:00 | Shipped | 2 | 5 | 2003 | ... | 59 rue de l'Abbaye | NaN | Reims | NaN | 51100 | France | EMEA | Henriot | Paul | Small |
| 2 | 10134 | 41 | 94.74 | 2 | 3884.34 | 7/1/2003 0:00 | Shipped | 3 | 7 | 2003 | ... | 27 rue du Colonel Pierre Avia | NaN | Paris | NaN | 75508 | France | EMEA | Da Cunha | Daniel | Medium |
| 3 | 10145 | 45 | 83.26 | 6 | 3746.70 | 8/25/2003 0:00 | Shipped | 3 | 8 | 2003 | ... | 78934 Hillside Dr. | NaN | Pasadena | CA | 90003 | USA | NaN | Young | Julie | Medium |
| 4 | 10159 | 49 | 100.00 | 14 | 5205.27 | 10/10/2003 0:00 | Shipped | 4 | 10 | 2003 | ... | 7734 Strong St. | NaN | San Francisco | CA | NaN | USA | NaN | Brown | Julie | Medium |
5 rows × 25 columns
kaggle_df["date"] = pd.to_datetime(kaggle_df.ORDERDATE)
kaggle_df.rename(columns={"PRODUCTLINE":"prod", "CITY":"cust", "QUANTITYORDERED":"demand", "SALES":"sales"}, inplace=True)
kaggle_demand_df = kaggle_df[["date","cust","prod","demand","sales"]].copy()
kaggle_demand_df.head()| date | cust | prod | demand | sales | |
|---|---|---|---|---|---|
| 0 | 2003-02-24 | NYC | Motorcycles | 30 | 2871.00 |
| 1 | 2003-05-07 | Reims | Motorcycles | 34 | 2765.90 |
| 2 | 2003-07-01 | Paris | Motorcycles | 41 | 3884.34 |
| 3 | 2003-08-25 | Pasadena | Motorcycles | 45 | 3746.70 |
| 4 | 2003-10-10 | San Francisco | Motorcycles | 49 | 5205.27 |
引数: - demand_df: 需要データフレーム(需要 demand と売り上げ sales の列を含む) - parent: 入れ子にする際の親項目; “cust” (既定値) もしくは “prod” を入れる. - value: 評価に使用する列名; 既定値は “demand” で, “sales” などを計算した列がデータフレーム内にあればそれを指定する.
返値: - Plotlyのtreemapオブジェクト
demand_tree_map (demand_df:pandas.core.frame.DataFrame, parent:str='cust', value:str='demand')
需要と売り上げのtreemapを生成する関数
sales列がない場合には,dataモジュールのdemand_attribute_compute関数を用いてsales(売り上げ)列を計算することができる。
需要のtreemapは,需要の大きさを面積とした階層図であり,売上は色で表現している.
fig = demand_tree_map(demand_df, parent ="prod", value = "demand");
#plotly.offline.plot(fig);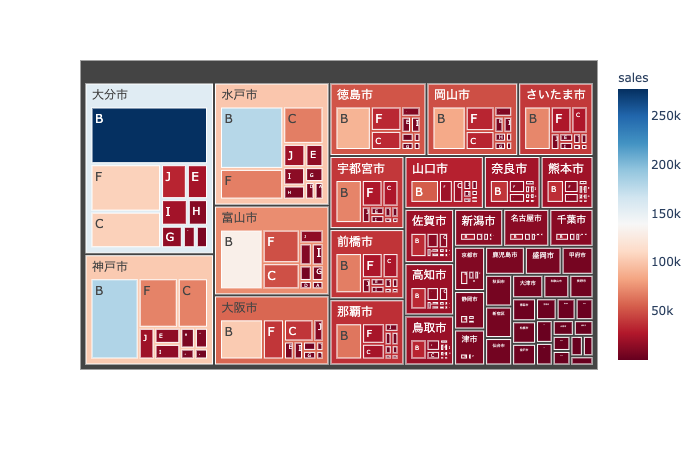
ABC分析のための関数を記述する、基本的には、需要データ demand_df だけあれば良いが、顧客や製品に関連した量を分析に加えたいときには、顧客データ cust_df や 製品データ prod_df も読み込んでおく。
古典的なABC分析では、3つのカテゴリーに製品や顧客を分類していたが、場合によっては4つに分類したい場合もあるだろう。 ここでは、より一般的にユーザーが与えた任意の数への分類を行う関数を準備する、カテゴリーに含まれる需要量を、ユーザーが与えた閾値をもとにして分類を行う。
引数:
返値: 以下の3つのオブジェクトのタプル:
abc_analysis (demand_df:pandas.core.frame.DataFrame, threshold:List[float], agg_col:str='prod', value:str='demand', abc_name:str='abc', rank_name:str='rank')
ABC分析のための関数
顧客・製品ごとに需要予測を行う際に,予測しなくても良い組を予め抜き出しておくことが重要になる.そのため,顧客・製品の組に対してABC分析とランク分析を行う関数を準備しておく.
引数:
返値: 以下の3つのオブジェクトのタプル:
abc_analysis_all (deamnd_df:pandas.core.frame.DataFrame, threshold:List[float])
以下では、製品と顧客に対してABC分析を行い、得られた3種類のデータフレーム(元のデータフレームに列を追加したもの:new_df、製品データフレームagg_df_prod、顧客データフレーム:agg_df_cust)を示す。
df = pd.DataFrame({"prod":[1,2,3,4,5], "demand": [10,30,40,50,80]})
threshold = [0.4, 0.5, 0.2]
agg_df, new_df, category = abc_analysis(df, threshold, "prod", "demand", "abc", "rank")
print(category)
new_df{0: ['5', '4'], 1: ['3', '2'], 2: ['1']}| prod | demand | abc | rank | |
|---|---|---|---|---|
| 0 | 1 | 10 | C | 4 |
| 1 | 2 | 30 | B | 3 |
| 2 | 3 | 40 | B | 2 |
| 3 | 4 | 50 | A | 1 |
| 4 | 5 | 80 | A | 0 |
demand_df = pd.read_csv(folder+"demand_with_promo_all.csv",index_col=0)
threshold = [0.4, 0.5, 0.1]
agg_df, new_df, category = abc_analysis(demand_df = demand_df, threshold=threshold,
agg_col="prod", value= "demand", abc_name="abc", rank_name="rank")
print(category)
new_df.head(){0: ['E', 'J', 'H'], 1: ['A', 'B', 'G', 'F', 'C', 'D'], 2: ['I']}| date | cust | prod | promo_0 | promo_1 | demand | abc | rank | |
|---|---|---|---|---|---|---|---|---|
| 0 | 2019-01-01 | 札幌市 | A | 0 | 0 | 6 | B | 3 |
| 1 | 2019-01-01 | 札幌市 | B | 0 | 0 | 6 | B | 4 |
| 2 | 2019-01-01 | 札幌市 | C | 0 | 0 | 6 | B | 7 |
| 3 | 2019-01-01 | 札幌市 | D | 0 | 0 | 5 | B | 8 |
| 4 | 2019-01-01 | 札幌市 | E | 0 | 0 | 11 | A | 0 |
agg_df_cust, new_df, category_cust = abc_analysis(
demand_df, [0.4, 0.3, 0.3, 0.1], 'cust', 'demand', "customer_ABC", "customer_rank")
new_df.head()| date | cust | prod | promo_0 | promo_1 | demand | customer_ABC | customer_rank | |
|---|---|---|---|---|---|---|---|---|
| 0 | 2019-01-01 | 札幌市 | A | 0 | 0 | 6 | C | 27 |
| 1 | 2019-01-01 | 札幌市 | B | 0 | 0 | 6 | C | 27 |
| 2 | 2019-01-01 | 札幌市 | C | 0 | 0 | 6 | C | 27 |
| 3 | 2019-01-01 | 札幌市 | D | 0 | 0 | 5 | C | 27 |
| 4 | 2019-01-01 | 札幌市 | E | 0 | 0 | 11 | C | 27 |
demand_df| date | cust | prod | promo_0 | promo_1 | demand | |
|---|---|---|---|---|---|---|
| 0 | 2019-01-01 | 札幌市 | A | 0 | 0 | 6 |
| 1 | 2019-01-01 | 札幌市 | B | 0 | 0 | 6 |
| 2 | 2019-01-01 | 札幌市 | C | 0 | 0 | 6 |
| 3 | 2019-01-01 | 札幌市 | D | 0 | 0 | 5 |
| 4 | 2019-01-01 | 札幌市 | E | 0 | 0 | 11 |
| ... | ... | ... | ... | ... | ... | ... |
| 343095 | 2020-12-30 | 那覇市 | F | 1 | 1 | 12 |
| 343096 | 2020-12-30 | 那覇市 | G | 1 | 1 | 12 |
| 343097 | 2020-12-30 | 那覇市 | H | 1 | 1 | 16 |
| 343098 | 2020-12-30 | 那覇市 | I | 1 | 1 | 10 |
| 343099 | 2020-12-30 | 那覇市 | J | 1 | 1 | 18 |
343100 rows × 6 columns
agg_df_cust.head()| demand | rank | abc | |
|---|---|---|---|
| cust | |||
| 佐賀市 | 566776 | 0 | A |
| 静岡市 | 308021 | 1 | A |
| 岡山市 | 257539 | 2 | A |
| 那覇市 | 158134 | 3 | A |
| 京都市 | 149615 | 4 | A |
agg_df,category = abc_analysis_all(demand_df, threshold=[0.4, 0.3, 0.3, 0.1])
#print(category)
agg_df.head()| sum | std | rank | abc | ||
|---|---|---|---|---|---|
| cust | prod | ||||
| 佐賀市 | E | 87858 | 59.304760 | 0 | A |
| J | 73705 | 49.763944 | 1 | A | |
| H | 63240 | 40.927453 | 2 | A | |
| A | 54031 | 38.126906 | 3 | A | |
| B | 52751 | 35.582571 | 4 | A |
引数: - df: 製品や顧客のデータフレーム;これにABC分析の結果を追加する. - agg_df: 集約した需要(もしくは売上),ABC分類,ランクを保管したデータフレーム;インデックスは製品(prod)もしくは顧客 (cust) - col_name: 追加したいデータの列名;製品の場合にはprod(既定値),顧客の場合にはcust - value: 追加したい列名;既定値は “demand”
返値: - df: ランク,ABC分類,集約した需要量を追加したデータフレーム
add_abc (df:pandas.core.frame.DataFrame, agg_df:pandas.core.frame.DataFrame, col_name:str='prod', value:str='demand')
cust_df = pd.read_csv(folder+"cust.csv", index_col=0)
new_cust_df = add_abc(df = cust_df, agg_df = agg_df_cust, col_name="cust", value="demand")
new_cust_df.head()| name | lat | lon | demand | rank | abc | |
|---|---|---|---|---|---|---|
| id | ||||||
| 1 | 札幌市 | 43.06417 | 141.34694 | 48954 | 27 | C |
| 2 | 青森市 | 40.82444 | 140.74000 | 80974 | 13 | B |
| 3 | 盛岡市 | 39.70361 | 141.15250 | 35997 | 43 | C |
| 4 | 仙台市 | 38.26889 | 140.87194 | 43341 | 32 | C |
| 5 | 秋田市 | 39.71861 | 140.10250 | 39103 | 38 | C |
引数: - demand_df: ABC分析の結果の列を含む需要データフレーム - abc_col: ABC分析の結果の列名
返値: - Plotlyのtreemapオブジェクト
demand_tree_map_with_abc (demand_df:pandas.core.frame.DataFrame, abc_col:str)
ABC別に色分けした需要のtreemapを生成する関数
agg_df_cust, new_df, category_cust = abc_analysis(
demand_df, [0.4, 0.3, 0.3, 0.1], 'cust', 'demand', "customer_ABC", "customer_rank")
fig = demand_tree_map_with_abc(new_df, abc_col="customer_ABC")
#plotly.offline.plot(fig);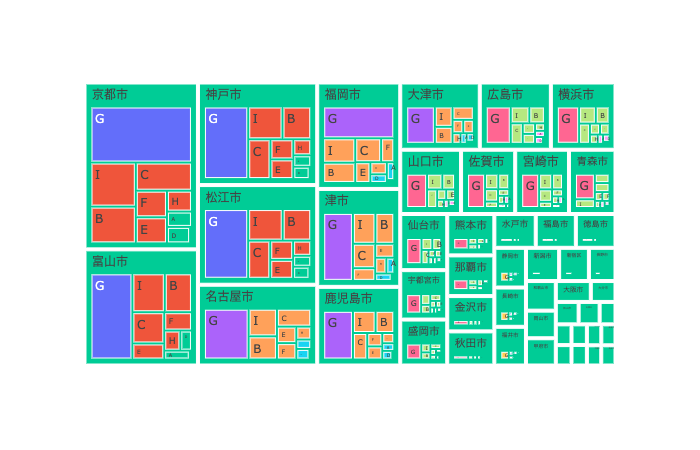
顧客と製品の両方に対するABC分析を同時に行い、結果の図とデータフレームを同時に得るには、この関数を用いる。
引数:
返値:
generate_figures_for_abc_analysis (demand_df:pandas.core.frame.DataFrame, value:str='demand', cumsum:bool=True, cust_thres:str='0.7, 0.2, 0.1', prod_thres:str='0.7, 0.2, 0.1')
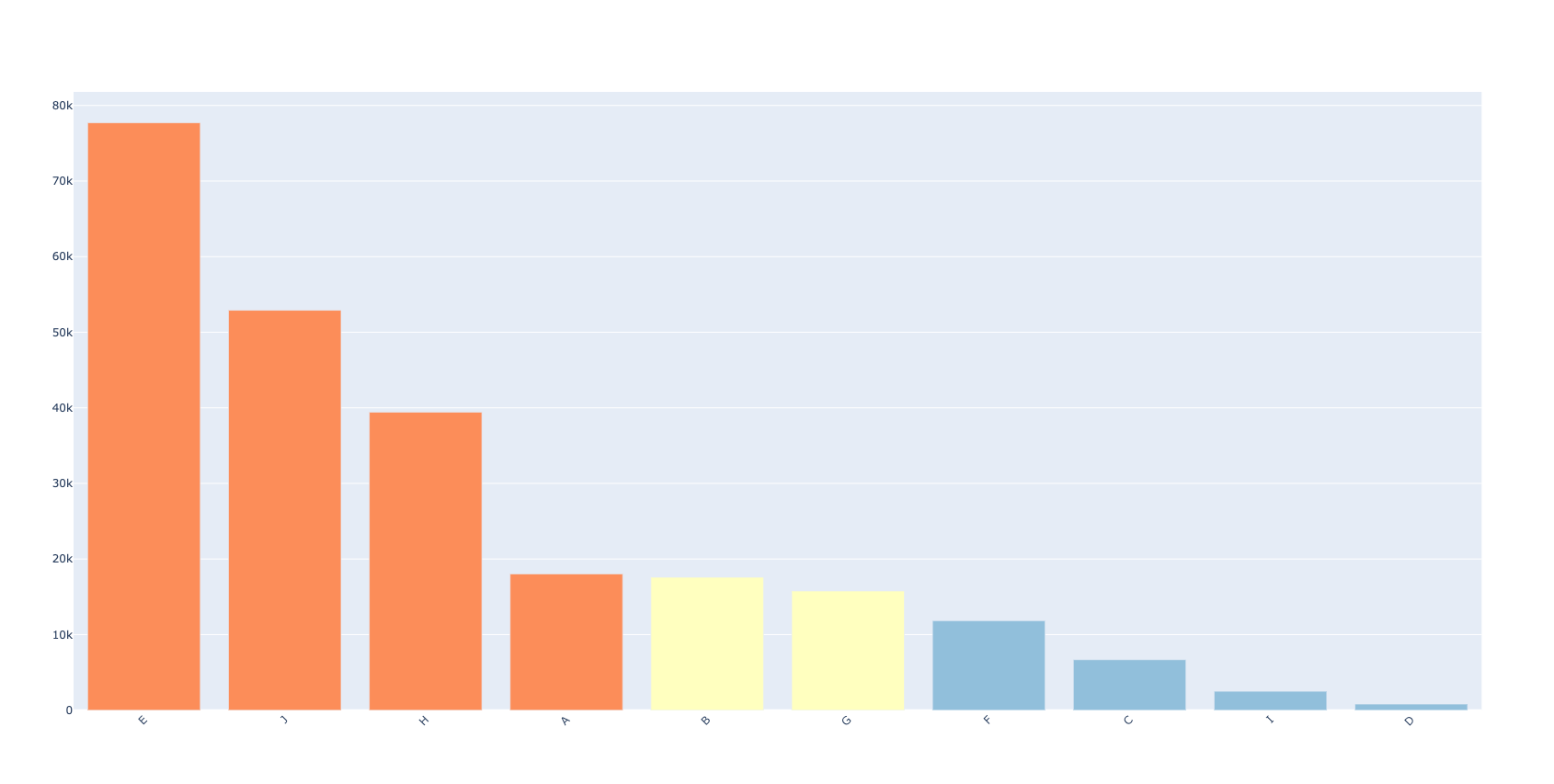
fig_prod, fig_cust, agg_df_prod, agg_df_cust, new_df, category_prod, category_cust = generate_figures_for_abc_analysis(
demand_df, value="demand", cumsum = False, cust_thres="0.7, 0.2, 0.1", prod_thres="0.7, 0.2, 0.1")
#plotly.offline.plot(fig_cust);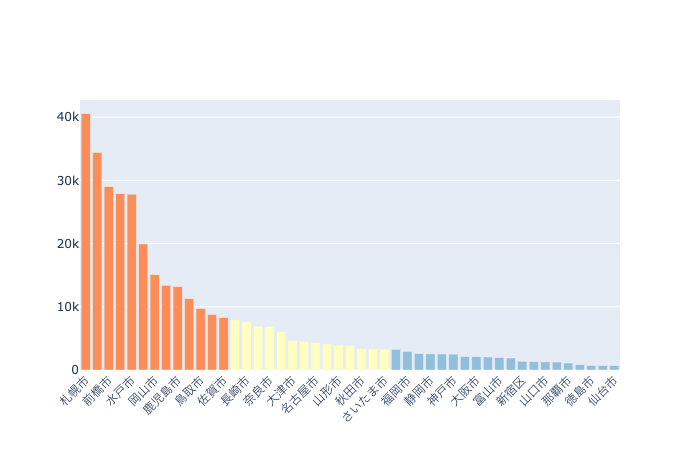
全ての期に対するランク分析を行う関数 rank_analysis と、期ごと(集約する単位は文字列で与える)のランク分析を行う関数 rank_analysis_all_periodsを記述する。
引数:
返値:
rank_analysis (df:pandas.core.frame.DataFrame, agg_col:str, value:str)
全期間分のランク分析のための関数
rank_analysis_all_periods (df:pandas.core.frame.DataFrame, agg_col:str, value:str, agg_period:str)
期別のランク分析のための関数
全期間分の顧客需要のランク分析と、3ヶ月を1期とした各期間に対する製品のランク分析。
dic = rank_analysis(df=demand_df, agg_col='cust', value='demand') #全ての期間に対する顧客需要量のランク分析
dic.popitem()('新潟市', 47)dic = rank_analysis_all_periods(df = demand_df, agg_col='prod', value= 'demand', agg_period="1d")ランクの時系列的な変化を表す図を生成するための関数。
引数:
返値:
show_rank_analysis (demand_df:pandas.core.frame.DataFrame, agg_df_prod:pandas.core.frame.DataFrame=None, value:str='demand', agg_period:str='1m', top_rank:int=1)
ランク分析の可視化関数
fig = show_rank_analysis(demand_df, value="demand", agg_period ="1d", top_rank = 10)
#plotly.offline.plot(fig);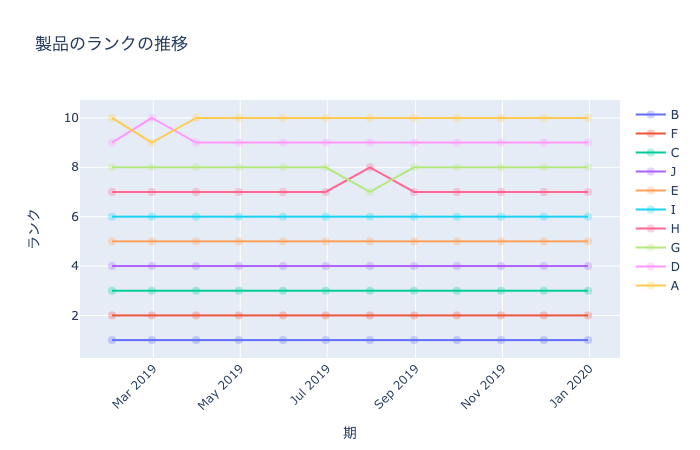
在庫をサプライ・チェインの上流(供給側)でもつか、下流(需要側)でもつかは、複数の需要地点(顧客)における需要の相関で決まる。 一般には、上流で在庫を共有することによって在庫の削減ができる。これをリスク共同管理 (risk pooling) とよぶ。
ここでは、製品ごとに、顧客の需要の標準偏差とリスク共同管理した場合の標準偏差の差を計算する。 また、それを需要の総量で割った比率(削減率)も計算する。 これは、標準偏差を平均値で割ることによる無次元の指標(変動係数: coefficient of variation: CV)に相当するものである。
この値が大きい製品ほど、リスク共同管理の効果が大きいので、サプライ・チェインの上流で在庫を保持した方が良いことになり、 逆に小さい製品ほど、下流で在庫を保持した方が良いことになる。
引数: - demand_df: 需要のデータフレーム - agg_period: 標準偏差を計算する際に用いる需要の集約を行う期(規定値は週)
返値: - inv_reduction_df : 標準偏差とその差と削減率を製品ごとに計算したデータフレーム; Rank列は製品の順位
risk_pooling_analysis (demand_df:pandas.core.frame.DataFrame, agg_period='1w')
リスク共同管理の効果を見るための関数
在庫を顧客側においた場合と、倉庫側においた場合の差を、標準偏差を計算することによって推定する。
1週間を単位とした標準偏差をもとに、在庫を倉庫に置いた場合と工場に置いた場合の差を計算し、それを需要の総量で除した削減率(ReductionRatioの列)を計算する。 Plotlyによる可視化では、削減率の大きいものから棒グラフで表示し、需要の大きさのランクで色分けをする。
inv_reduction_df = risk_pooling_analysis(demand_df, agg_period="1w")
inv_reduction_df.head()| rank | prod | agg_std | sum_std | reduction | |
|---|---|---|---|---|---|
| 0 | 10 | I | 1137.883708 | 1138.748290 | 0.864583 |
| 1 | 8 | C | 1120.054537 | 1120.794951 | 0.740414 |
| 2 | 9 | D | 1114.387806 | 1115.096672 | 0.708866 |
| 3 | 4 | A | 1363.027889 | 1363.691051 | 0.663161 |
| 4 | 7 | F | 1282.927125 | 1283.552063 | 0.624938 |
show_inventory_reduction (inv_reduction_df:pandas.core.frame.DataFrame)
在庫削減量の可視化関数
fig = show_inventory_reduction(inv_reduction_df)
#plotly.offline.plot(fig);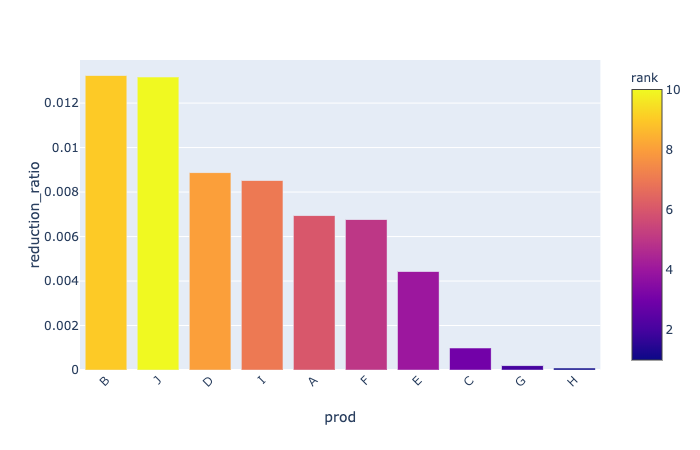
需要を製品ごとに集約し,横軸に平均,縦軸に変動係数(\(CV=\sigma/\mu\))の対数をとった散布図を生成する.
平均が大きく,変動係数が小さい製品は安定しているので倉庫(サプライ・チェインの下流)で保管し,平均が小さく変動係数が大きい製品は,工場(サプライ・チェインの上流)で 保管し,適宜顧客側に流す戦略が望ましい. また,平均が小さく,変動係数も小さい製品に対しては,さらに利益によって細分化したサプライ・チェイン戦略をとる必要がある. 利益の大きい製品は在庫費用も大きいので,サプライ・チェインの上流(工場側)で管理し,必要に応じて下流に流し, 利益の小さい製品は下流(倉庫側)で保管する.
製品ごとに同一のサプライ・チェイン戦略をとるのではなく,減り張りをつけて改善することによって,応答性(顧客サービス)と効率性を高めることができる.
引数: - demand_df: 需要データフレーム - prod_df: 製品データフレーム(オプション); 製品の在庫費用 (cust_calue) を表示するために用いる. - show_name: Trueのとき製品名も描画する.
返値: - fig: Plotlyの図オブジェクト
show_mean_cv (demand_df:pandas.core.frame.DataFrame, prod_df:Optional[pandas.core.frame.DataFrame]=None, show_name:bool=True)
fig = show_mean_cv(demand_df, prod_df, show_name=True)
#plotly.offline.plot(fig);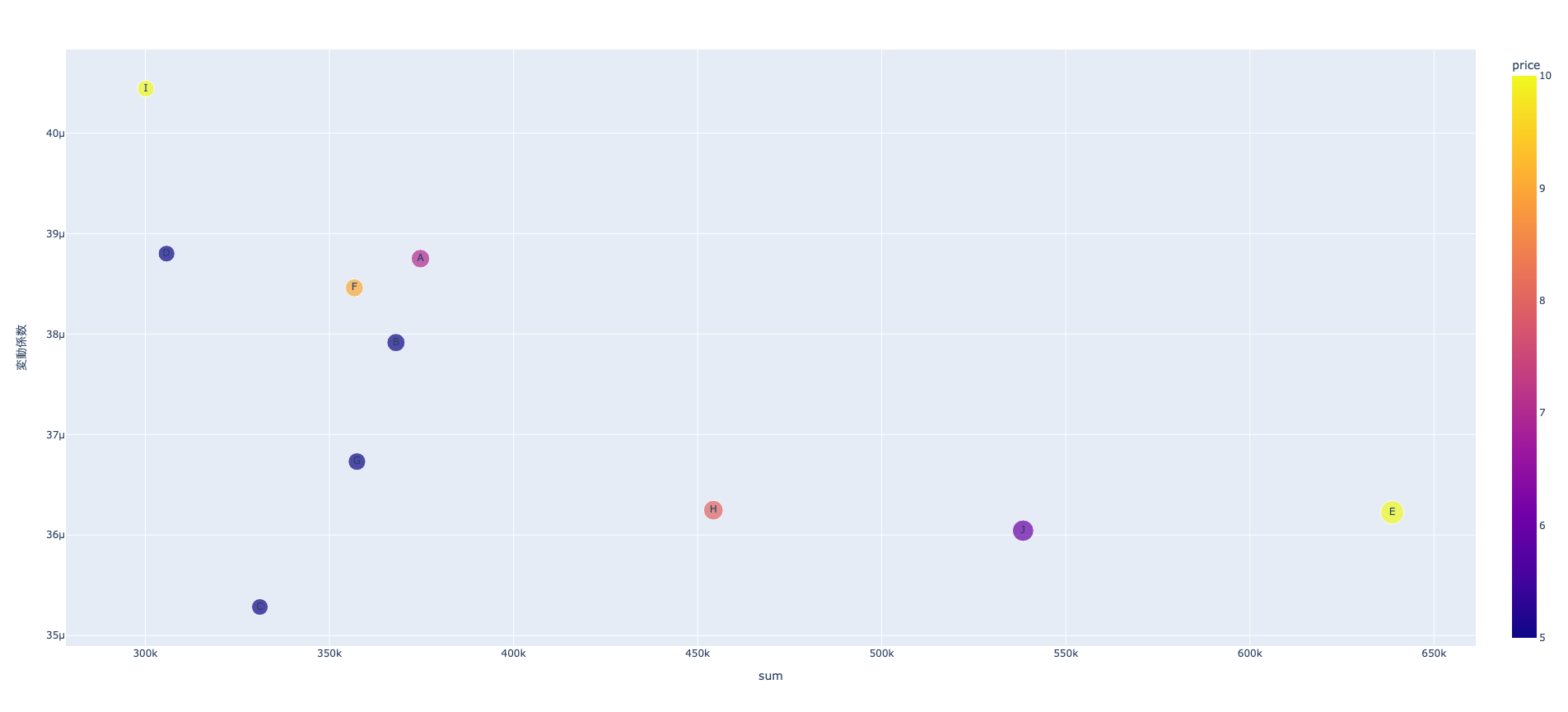
全ての需要が1つの工場で生産していると仮定したとき、その生産ロットサイズや安全在庫量は、古典的な経済発注量モデルと新聞売り子モデルで計算できる。
安全在庫量: 安全在庫係数 \(z\), リード時間 \(L\), 需要の標準偏差 \(\sigma\) としたとき \(z\sqrt{LT}\sigma\)
経済発注量(生産ロットサイズ): 生産固定費用 \(FC\)、需要の平均値 \(d\)、在庫費用 \(h\) としたとき \(\sqrt{2 FCd/h}\)
保管費率(無次元): \(r\) は以下の量の和とする。
在庫費用: \(h\) は、保管費率 \(r\) に製品の価値(製品データのplnt_value列)を乗じたものを週あたりに換算したもの
目標在庫量 \(=\) 基在庫レベル: 安全在庫量 \(+\) リード時間内の需要量
初期在庫量 \(=\) 目標在庫量に生産ロットサイズの半分を加えた量
引数:
返値: 以下の列情報を加えた製品データフレーム prod_df
inventory_analysis (prod_df:pandas.core.frame.DataFrame, demand_df:pandas.core.frame.DataFrame, inv_reduction_df:pandas.core.frame.DataFrame, z:float=1.65, LT:int=1, r:float=0.3, num_days:int=7)
工場における安全在庫量の計算
工場を1箇所に集約したと仮定する。複数工場の場合には、顧客と工場の紐付け情報が必要になる。
1週間を基本単位として、在庫量削減データフレームを計算し、それをもとに工場での在庫量を求める。
prod_df = pd.read_csv(folder+"prod.csv",index_col=0)
inv_reduction_df = risk_pooling_analysis(demand_df, agg_period="1w")
new_prod_df = inventory_analysis(prod_df, demand_df, inv_reduction_df, z = 1.65, LT = 1, r = 0.3, num_days=7)
#prod_df2.to_csv(folder + "prod_with_inventory.csv")
new_prod_df.head()| name | weight | volume | cust_value | dc_value | plnt_value | fixed_cost | average_demand | standard_deviation | inv_cost | lot_size | safety_inventory | target_inventory | initial_inventory | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| index | ||||||||||||||
| 0 | A | 2 | 0 | 7 | 1 | 1 | 14 | 3598.172840 | 1363.027889 | 0.005753 | 4184.627560 | 2248.996017 | 5847.168857 | 5171.996017 |
| 1 | B | 5 | 0 | 5 | 1 | 1 | 14 | 3534.347051 | 1322.720355 | 0.005753 | 4147.347222 | 2182.488585 | 5716.835636 | 5040.488585 |
| 2 | C | 1 | 0 | 5 | 1 | 1 | 19 | 3179.353909 | 1120.054537 | 0.005753 | 4582.453009 | 1848.089986 | 5027.443895 | 4361.089986 |
| 3 | D | 3 | 0 | 5 | 1 | 1 | 17 | 2935.995885 | 1114.387806 | 0.005753 | 4165.373643 | 1838.739880 | 4774.735764 | 4225.739880 |
| 4 | E | 1 | 0 | 10 | 1 | 1 | 18 | 6132.412894 | 2192.456416 | 0.005753 | 6194.463943 | 3617.553086 | 9749.965980 | 8491.553086 |
上で生成したデータを用いて、シミュレーションを行う。生産は、安全在庫量を下回ったときに行われ、目標在庫量になるように生産量を決める。
TODO: NumPyで高速化, 様々な発注方策に対応
引数:
返値:
inventory_simulation (prod_df:pandas.core.frame.DataFrame, demand_df:pandas.core.frame.DataFrame)
(Q,R)方策のシミュレーション
製品 A に対する需要、在庫、生産量を表すデータフレームを表示する。
production_df = inventory_simulation(new_prod_df, demand_df)
production_df[prod_df.name[0]].head()| demand | inventory | production | |
|---|---|---|---|
| 2019-01-01 | 475 | 4696.996017 | 0.0 |
| 2019-01-02 | 688 | 4008.996017 | 0.0 |
| 2019-01-03 | 555 | 3453.996017 | 0.0 |
| 2019-01-04 | 449 | 3004.996017 | 0.0 |
| 2019-01-05 | 607 | 2397.996017 | 0.0 |
引数:
返値:
show_prod_inv_demand (prod_name:str, production_df:pandas.core.frame.DataFrame, scale:str='1d')
生産、在庫、需要の可視化関数
fig = show_prod_inv_demand(prod_df.name[3], production_df, scale="1d")
#plotly.offline.plot(fig);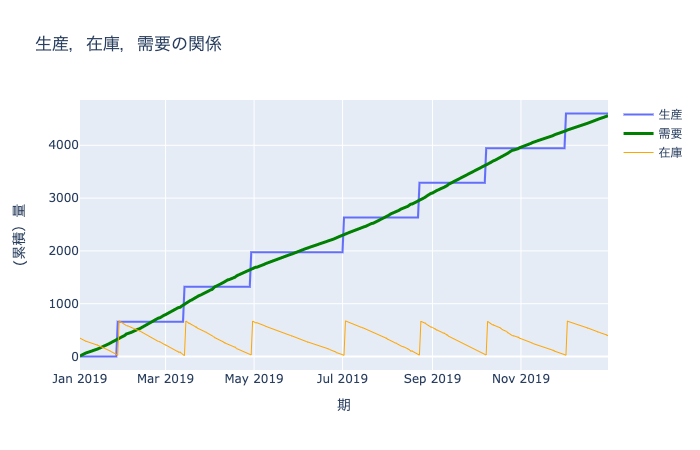
plot_demands (prod_cust_list:List[str], demand_df:pandas.core.frame.DataFrame, agg_period:str='1d')
需要の可視化関数
prod_cust_list = ["A,さいたま市","B,さいたま市", "E,佐賀市"]
fig = plot_demands(prod_cust_list, demand_df, agg_period="2w")上の関数を元にクラスを作る.
Scbas (demand_df:pandas.core.frame.DataFrame, agg_df_prod:Optional[pandas.core.frame.DataFrame]=None, agg_df_cust:Optional[pandas.core.frame.DataFrame]=None, new_demand_df:Optional[pandas.core.frame.DataFrame]=None, reduction_df:Optional[pandas.core.frame.DataFrame]=None, new_prod_df:Optional[pandas.core.frame.DataFrame]=None, category_prod:Optional[Dict[int,List[str]]]=None, category_cust:Optional[Dict[int,List[str]]]=None, nodes:Optional[List[Dict]]=None, agg_period:str=('1w',))
Usage docs: https://docs.pydantic.dev/2.6/concepts/models/
A base class for creating Pydantic models.
Attributes: class_vars: The names of classvars defined on the model. private_attributes: Metadata about the private attributes of the model. signature: The signature for instantiating the model.
__pydantic_complete__: Whether model building is completed, or if there are still undefined fields.
__pydantic_core_schema__: The pydantic-core schema used to build the SchemaValidator and SchemaSerializer.
__pydantic_custom_init__: Whether the model has a custom `__init__` function.
__pydantic_decorators__: Metadata containing the decorators defined on the model.
This replaces `Model.__validators__` and `Model.__root_validators__` from Pydantic V1.
__pydantic_generic_metadata__: Metadata for generic models; contains data used for a similar purpose to
__args__, __origin__, __parameters__ in typing-module generics. May eventually be replaced by these.
__pydantic_parent_namespace__: Parent namespace of the model, used for automatic rebuilding of models.
__pydantic_post_init__: The name of the post-init method for the model, if defined.
__pydantic_root_model__: Whether the model is a `RootModel`.
__pydantic_serializer__: The pydantic-core SchemaSerializer used to dump instances of the model.
__pydantic_validator__: The pydantic-core SchemaValidator used to validate instances of the model.
__pydantic_extra__: An instance attribute with the values of extra fields from validation when
`model_config['extra'] == 'allow'`.
__pydantic_fields_set__: An instance attribute with the names of fields explicitly set.
__pydantic_private__: Instance attribute with the values of private attributes set on the model instance.scbas = Scbas(demand_df=demand_df, agg_period= "1w")
fig = scbas.demand_tree_map(parent ="prod", value = "demand")
#plotly.offline.plot(fig);fig_prod, fig_cust, agg_df_prod, agg_df_cust, new_df, category_prod, category_cust = scbas.generate_figures_for_abc_analysis(
value="demand", cumsum = False, cust_thres="0.7, 0.2, 0.1", prod_thres="0.7, 0.2, 0.1"
)
#plotly.offline.plot(fig_cust);
#scbas.nodesfig = scbas.show_rank_analysis(value="demand", top_rank = 10)
#plotly.offline.plot(fig);reduction_df = scbas.risk_pooling_analysis()
reduction_df.head()| rank | prod | agg_std | sum_std | reduction | |
|---|---|---|---|---|---|
| 0 | 10 | I | 1137.883708 | 1138.748290 | 0.864583 |
| 1 | 8 | C | 1120.054537 | 1120.794951 | 0.740414 |
| 2 | 9 | D | 1114.387806 | 1115.096672 | 0.708866 |
| 3 | 4 | A | 1363.027889 | 1363.691051 | 0.663161 |
| 4 | 7 | F | 1282.927125 | 1283.552063 | 0.624938 |
scbas = Scbas(demand_df=demand_df, agg_period= "1w")
fig = scbas.show_mean_cv(prod_df=prod_df, show_name=True)
#plotly.offline.plot(fig);scbas = Scbas(demand_df=demand_df, agg_period= "1w")
prod_df = pd.read_csv(folder+"prod.csv",index_col=0)
new_prod_df = scbas.inventory_analysis(prod_df, z = 1.65, LT = 1, r = 0.3, num_days=7)
new_prod_df.head().T| index | 0 | 1 | 2 | 3 | 4 |
|---|---|---|---|---|---|
| name | A | B | C | D | E |
| weight | 2 | 5 | 1 | 3 | 1 |
| volume | 0 | 0 | 0 | 0 | 0 |
| cust_value | 7 | 5 | 5 | 5 | 10 |
| dc_value | 1 | 1 | 1 | 1 | 1 |
| plnt_value | 1 | 1 | 1 | 1 | 1 |
| fixed_cost | 14 | 14 | 19 | 17 | 18 |
| average_demand | 3598.17284 | 3534.347051 | 3179.353909 | 2935.995885 | 6132.412894 |
| standard_deviation | 1363.027889 | 1322.720355 | 1120.054537 | 1114.387806 | 2192.456416 |
| inv_cost | 0.005753 | 0.005753 | 0.005753 | 0.005753 | 0.005753 |
| lot_size | 4184.62756 | 4147.347222 | 4582.453009 | 4165.373643 | 6194.463943 |
| safety_inventory | 2248.996017 | 2182.488585 | 1848.089986 | 1838.73988 | 3617.553086 |
| target_inventory | 5847.168857 | 5716.835636 | 5027.443895 | 4774.735764 | 9749.96598 |
| initial_inventory | 5171.996017 | 5040.488585 | 4361.089986 | 4225.73988 | 8491.553086 |