# demand_df = pd.read_csv(folder+"demand_all.csv")
# cust_selected = ["佐賀市"]
# prod_selected = ["F"]
# print(cust_selected, prod_selected)
# dic, df = forecast_demand(demand_df, cust_selected, prod_selected, agg_period ="1d", forecast_periods =10,
# cumulative=False, lb=0., ub=None, growth ="linear",
# daily_seasonality=False, weekly_seasonality=True, yearly_seasonality=True,
# n_lags=10)
# print(cust_selected[0], prod_selected[0])
# #if dic[ cust_selected[0], prod_selected[0] ] is not None:
# model, forecast = dic[ cust_selected[0], prod_selected[0] ]
# #model.plot(forecast)
# # else:
# # print("too few data")需要予測モジュールforecastと予測システム ABD-Forecast
予測手法と予測システム ABD-Forecast (AutoML Bayes Deep Forecast)
NeuralProphet
顧客の需要予測
過去の需要系列dfをもとに、NeuralProphetによる予測を行う関数 forecast_demand を準備する。 比較として、(需要の定常性を仮定して) 平均と標準偏差も算出する。
引数:
- demand_df: 需要の系列を表すデータフレーム。顧客Cust、製品Prod,日時Date、需要量demandの列をもつものと仮定する。
- cust_selected: 顧客のリスト
- prod_selected: 製品のリスト
- agg_period: 集約を行う期。例えば1週間を1期とするなら”1w”とする。既定値は1日(“1d”)
- forecast_period: 予測を行う未来の期数。既定値は1
- cumulative: 累積需要量を用いて予測するとき True;既定値はFalse
- lb: 下限値(傾向変動がロジスティック曲線の場合に有効になる.)既定値は0.
- ub: 上限値(傾向変動がロジスティック曲線の場合に有効になる.)既定値は Noneで,その場合にはデータの最大値が設定される.
- kwargs: その他のNeuralProphetのキーワード引数
NeuralProphetの引数と既定値:
- changepoints=None : 傾向変更点のリスト
- changepoint_range = \(0.8\) : 傾向変化点の候補の幅(先頭から何割を候補とするか)
- n_changepoints= \(10\) : 傾向変更点の数
- trend_reg = \(0\) : 傾向変動の正則化パラメータ
- yearly_seasonality=
auto: 年次の季節変動を考慮するか否か - weekly_seasonality=
auto: 週次の季節変動を考慮するか否か - daily_seasonality=
auto: 日次の季節変動を考慮するか否か - seasonality_mode =
additive: 季節変動が加法的(additive)か乗法的(multiplicative)か - seasonality_reg= \(0\) : 季節変動の正則化パラメータ
- n_forecasts = \(1\) : 予測数
- n_lags = \(0\): 時間ずれ(ラグ)
- ar_reg = \(0\): 自己回帰の正則化パラメータ
- quantile= \([]\) : 不確実性を表示するための分位数のリスト
返値:
以下の情報を列情報にもつデータフレーム
- dic: 顧客と製品のタプルをキーとし、モデルと予測オブジェクトのタプルを値とした辞書
forecast_demand
forecast_demand (demand_df, cust_selected, prod_selected, agg_period='1d', forecast_periods=1, cumulative=False, lb=0.0, ub=None, **kwargs)
NeuralProphetを用いた需要予測(顧客と製品に対して)
forecast_demand関数の使用例
#model.plot_parameters(components=["seasonality"])
#model.plot_components(forecast)
#model.plot_parameters(components=["autoregression"])特徴量を入れたProphetによる需要予測
promotionも顧客,製品に依存するので,現在のpromoではよくない. prod, cust, promo_1, promo_2 の形式で未来のデータも作成する!
過去の需要系列demand_dfとプロモーション情報promo_dfを用いてProphetによる予測を行う関数 forecast_demand_with_featuresを準備する。
引数:
- demand_df: 需要の系列を表すデータフレーム。顧客Cust、製品Prod,日時Date、需要量demandの列をもつものと仮定する。
- cust_selected: 顧客のリスト
- prod_selected: 製品のリスト
- promo_df: プロモーション情報を入れたデータフレーム;demand_dfと同じ日時と、予測する期間に対する日時の情報を含むものとする。
- feature: promo_df内で特徴量として用いる列名のリスト
- agg_period: 集約を行う期。例えば1週間を1期とするなら”1w”とする。既定値は1日(“1d”)
- forecast_period: 予測を行う未来の期数。既定値は1
- cumulative: 累積需要量を用いて予測するとき True;既定値はFalse
- lb: 下限値(傾向変動がロジスティック曲線の場合に有効になる.)既定値は0.
- ub: 上限値(傾向変動がロジスティック曲線の場合に有効になる.)既定値は Noneで,その場合にはデータの最大値が設定される.
- kwargs: その他のNeuralProphetのキーワード引数
NeuralProphetの引数と既定値:
- changepoints=None : 傾向変更点のリスト
- changepoint_range = \(0.8\) : 傾向変化点の候補の幅(先頭から何割を候補とするか)
- n_changepoints= \(10\) : 傾向変更点の数
- trend_reg = \(0\) : 傾向変動の正則化パラメータ
- yearly_seasonality=
auto: 年次の季節変動を考慮するか否か - weekly_seasonality=
auto: 週次の季節変動を考慮するか否か - daily_seasonality=
auto: 日次の季節変動を考慮するか否か - seasonality_mode =
additive: 季節変動が加法的(additive)か乗法的(multiplicative)か - seasonality_reg= \(0\) : 季節変動の正則化パラメータ
- n_forecasts = \(1\) : 予測数
- n_lags = \(0\): 時間ずれ(ラグ)
- ar_reg = \(0\): 自己回帰の正則化パラメータ
- quantile= \([]\) : 不確実性を表示するための分位数のリスト
返値:
- dic: 顧客と製品のタプルをキーとし、モデルと予測オブジェクトのタプルを値とした辞書
- df: 予測に用いたデータフレーム(顧客と製品に対しての時系列データ)
forecast_demand_with_features
forecast_demand_with_features (demand_df, cust_selected, prod_selected, promo_df=None, features=None, agg_period='1d', forecast_periods=1, cumulative=False, lb=0.0, ub=None, **kwargs)
Prophetを用いた需要予測(顧客と製品に対して):特徴ベクトルの追加
forecast_demand_with_features関数の使用例
# promo_df = pd.read_csv(folder+"promo.csv", index_col=0)
# demand_df = pd.read_csv(folder+"demand_with_promo.csv")
# cust_selected = [ demand_df["cust"].iloc[90],demand_df["cust"].iloc[101] ]
# prod_selected = [ demand_df["prod"].iloc[1] ]
# #cust_selected = ["前橋市"]
# #prod_selected = ["F"]
# print(cust_selected, prod_selected)
# dic, df = forecast_demand_with_features(demand_df, cust_selected, prod_selected, promo_df, features=['promo_0', 'promo_1'],
# agg_period ="1d", forecast_periods =0, cumulative=False, growth="linear",
# daily_seasonality=False, weekly_seasonality=True, yearly_seasonality=True,n_lags=10)
# #accelerator="mps") #for Apple sillicone 余計遅くなる?
# if dic[ cust_selected[0], prod_selected[0] ] is not None:
# model, forecast = dic[ cust_selected[0], prod_selected[0] ]
# model.plot(forecast);
# else:
# print("too few data")#model.plot(forecast)
#model.plot_parameters(components=["seasonality"])
#model.plot_components(forecast)
#model.plot_parameters(components=["autoregression"])深層学習ライブラリ fastai を用いた需要予測
Excelのテンプレートを生成する関数 make_excel_forecast
Excelインターフェイスのテンプレートを生成する関数.
引数:
- start: 開始日
- finish: 終了日
- period: 期を構成する単位期間の数;既定値は \(1\)
- period_unit: 期の単位 (時,日,週,月から選択); 既定値は日; periodとあわせて期間の生成に用いる. たとえば,既定値だと1日が1期となる.
- num_features: (休日を除く)特徴の数
- holiday: 日本のカレンダーに基づく休日を表す特徴を追加するときTrue
返値:
- 需要予測用のExcelのWorkbook
make_excel_forecast
make_excel_forecast (start, finish, period=1, period_unit='日', num_features=0, holiday=True)
make_excel_forecast関数の使用例
start = '2015-01-05' #開始日
finish = '2019-1-30'
period=1
period_unit="週"
wb = make_excel_forecast(start, finish, period, period_unit, num_features = 0, holiday=False)
#wb.save("forecast-templete.xlsx")Excelファイルを読み込んで予測を行う関数 forecast_excel
ExcelのWorkbookを与えると予測を記入して返す関数
引数: - wb: 日付,需要,特徴のデータを入れたExcel Workbook - valid_start: 検証開始日 - predict_start: 予測開始日
返値: - wb: 予測結果と誤差の列を追加したExcel Workbook - best: 最良の予測をしたモデルオブジェクト - result_df: 予測結果のデータフレーム - forecast: 最良の予測モデルを用いた予測結果のデータフレーム - demand_df: 予測結果から需要を抽出し,誤差列を追加したデータフレーム - valid_df: demand_dfから検証開始から予測開始の直前までを抜き出したデータフレーム
forecast_excel
forecast_excel (wb, valid_start, predict_start)
forecast_excel関数の使用例
予測に基づく動的発注量シートの生成関数 dynamic_inv_excel
引数: - wb: 在庫シミュレーションシートを入れるExcel Workbook - valid_start: 検証開始日 - predict_start: 予測開始日 - valid_df: demand_dfから検証開始から予測開始の直前までを抜き出したデータフレーム - demand_df: 予測結果から需要を抽出し,誤差列を追加したデータフレーム - h: 在庫費用(定数かリスト); 関数内で需要と同じ長さのNumPy配列に変換される. - fc: 固定費用(定数かリスト); 関数内で需要と同じ長さのNumPy配列に変換される. - vc: 変動費用(定数かリスト); 関数内で需要と同じ長さのNumPy配列に変換される;既定値は0. - z: 安全在庫係数;初期安全在庫量を決めるために使われる定数(既定値は2.33)
返値: - wb: 在庫シミュレーションシートを追加したExcel Workbook
dynamic_inv_excel
dynamic_inv_excel (wb, valid_start, predict_start, valid_df, demand_df, h, fc, vc=0.0, z=2.33)
dynamic_inv_excel関数の使用例
未来の時系列データフレームを生成する関数 make_future_dataframe
過去の時系列データから未来のデータを生成する関数
- history_dates: 過去の時系列データの日付を表す
- periods: 生成する未来の期数
- freq: 生成する期の単位(頻度)を表す文字列; たとえば,1日単位の場合には”1d”とする.
make_future_dataframe
make_future_dataframe (history_dates, periods, freq='1d')
未来の時系列データフレームを生成する関数
make_future_dataframe関数の使用例
df = pd.read_csv(folder+"a_demand.csv", index_col=0)
df.head()| date | demand | promo_0 | promo_1 | |
|---|---|---|---|---|
| 0 | 2019-01-01 | 5.0 | 0.0 | 0.0 |
| 1 | 2019-01-02 | 6.0 | 1.0 | 0.0 |
| 2 | 2019-01-03 | 6.0 | 0.0 | 0.0 |
| 3 | 2019-01-04 | 5.0 | 0.0 | 0.0 |
| 4 | 2019-01-05 | 7.0 | 0.0 | 0.0 |
future = make_future_dataframe(history_dates=df["date"], periods=10, freq="1d")
future.tail()| date | |
|---|---|
| 5 | 2021-01-05 |
| 6 | 2021-01-06 |
| 7 | 2021-01-07 |
| 8 | 2021-01-08 |
| 9 | 2021-01-09 |
顧客と製品を与えると、訓練用データフレームと予測用の未来のデータフレームを生成する関数 make_forecast_df
需要がない日を自動的に追加し,その需要を0と補完する. さらに,日付時刻のデータを様々な特徴に分解する.
引数: - df: 1つの顧客と製品に対する需要データフレーム - promo_df: 追加特徴(プロモーション)情報を含んだデータフレーム(オプション); - 予測期間に対しても追加情報を準備する必要がある. 予測期間内のデータが空 (NaN)の場合には,訓練データにも空 (NaN)のものがある必要がある. - agg_period: 期間を表す文字列(例えば1日のときは”1d”) - forecast_periods: 予測したい期間
返値: - train: 訓練用データフレーム - future: 予測予測の未来のデータを入れたデータフレーム (過去も含めたい場合には pd.concatで合併する.)
make_forecast_df
make_forecast_df (df, promo_df=None, agg_period='1d', forecast_periods=1)
訓練用データフレームと予測用の未来のデータフレームを生成する関数
make_forecast_df関数の使用例
# cust_df = pd.read_csv(folder+"cust.csv")
# prod_df = pd.read_csv(folder+"prod.csv")
promo_df = pd.read_csv(folder+"promo.csv", index_col=0)
train, future = make_forecast_df(df, promo_df= promo_df, agg_period="1d", forecast_periods = 10)
train.head()| demand | promo_0 | promo_1 | Year | Month | Week | Day | Dayofweek | Dayofyear | Is_month_end | Is_month_start | Is_quarter_end | Is_quarter_start | Is_year_end | Is_year_start | Elapsed | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 5.0 | 0.0 | 0.0 | 2019 | 1 | 1 | 1 | 1 | 1 | False | True | False | True | False | True | 1.546301e+09 |
| 1 | 6.0 | 1.0 | 0.0 | 2019 | 1 | 1 | 2 | 2 | 2 | False | False | False | False | False | False | 1.546387e+09 |
| 2 | 6.0 | 0.0 | 0.0 | 2019 | 1 | 1 | 3 | 3 | 3 | False | False | False | False | False | False | 1.546474e+09 |
| 3 | 5.0 | 0.0 | 0.0 | 2019 | 1 | 1 | 4 | 4 | 4 | False | False | False | False | False | False | 1.546560e+09 |
| 4 | 7.0 | 0.0 | 0.0 | 2019 | 1 | 1 | 5 | 5 | 5 | False | False | False | False | False | False | 1.546646e+09 |
全てのデータを用いて深層学習による予測をするためのデータフレームの生成関数
データ数が不足している場合には、顧客や製品もカテゴリー変数として扱うことによって十分なデータを確保することができる。
引数: - demand_df: 需要データフレーム - promo_df: 追加特徴(プロモーション)情報を含んだデータフレーム(オプション);予測期間に対しても追加情報を準備する必要がある. 予測期間内のデータが空 (NaN)の場合には,訓練データにも空 (NaN)のものがある必要がある. - agg_period: 期間を表す文字列(例えば1日のときは”1d”)
返値: - train: 訓練用データフレーム
make_forecast_df_all
make_forecast_df_all (demand_df, promo_df=None, agg_period='1d', forecast_periods=1)
全データに対する訓練用データフレームを生成する関数
# 訓練に時間がかかるので注意
agg_period="1d"
demand_df = pd.read_csv(folder+"demand_with_promo_all.csv", index_col=0)
train, future = make_forecast_df_all(demand_df, promo_df, agg_period="1d")
future.head()| cust | prod | promo_0 | promo_1 | Year | Month | Week | Day | Dayofweek | Dayofyear | Is_month_end | Is_month_start | Is_quarter_end | Is_quarter_start | Is_year_end | Is_year_start | Elapsed | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 熊本市 | A | 0 | 0 | 2020 | 12 | 53 | 31 | 3 | 366 | True | False | True | False | True | False | 1.609373e+09 |
| 1 | 熊本市 | C | 0 | 0 | 2020 | 12 | 53 | 31 | 3 | 366 | True | False | True | False | True | False | 1.609373e+09 |
| 2 | 熊本市 | E | 0 | 0 | 2020 | 12 | 53 | 31 | 3 | 366 | True | False | True | False | True | False | 1.609373e+09 |
| 3 | 熊本市 | F | 0 | 0 | 2020 | 12 | 53 | 31 | 3 | 366 | True | False | True | False | True | False | 1.609373e+09 |
| 4 | 熊本市 | D | 0 | 0 | 2020 | 12 | 53 | 31 | 3 | 366 | True | False | True | False | True | False | 1.609373e+09 |
検証期間を設定するための関数 find_horizon
find_horizon
find_horizon (demand_df, ratio=0.9)
demand_df = pd.read_csv(folder+"demand_with_promo_all.csv")
find_horizon(demand_df, ratio=0.9)Timestamp('2020-10-19 00:00:00')訓練データと検証データのインデックスを準備する関数 prepare_index
引数:
- df: 日付情報(Year列、Month列、Day列)を含んだデータフレーム
- horizon: 検証データを作成するときの閾値の日付;この日付より後のデータは検証データになる。Noneのときには,全体の約 10%を検証データとする。
返値: - train_idx: 訓練データのインデックス - valid_idx: 検証データのインデックス
prepare_index
prepare_index (df, horizon=None)
train_idx, valid_idx =prepare_index(train, horizon="2020/11/21")
len(train_idx), len(valid_idx)(324770, 18330)訓練
需要を連続量とする場合と離散量とする場合で異なる予測を行う。連続量の場合には回帰問題となり、離散量の場合には分類問題になる。
学習器を作成する関数 make_learn
引数:
- df: 日付 (date)と需要 (deman),もしくは顧客(cust),製品(cust),その他の特徴量の列を含んだ訓練用データフレーム
- horizon: 検証データを作成するときの閾値の日付;この日付より後のデータは検証データになる。
- classification: 分類問題としてモデルを作成する場合にはTrue、回帰問題としてモデルを作成する場合には Falseを入れる。
返値:
- learn: fastaiの学習器
make_learn
make_learn (df, horizon=None, classification=False)
深層学習を用いた需要予測用のデータを生成
make_learn関数の使用例
learn = make_learn(train, horizon="2020-10-01", classification=False)適正な学習率を見つけるための関数 lr_find
lr_min= learn.lr_find()
print(lr_min)SuggestedLRs(valley=0.0020892962347716093)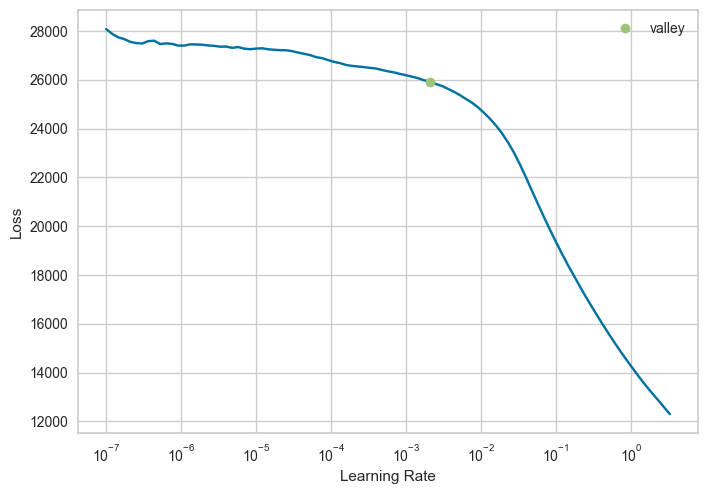
# fig = plot_lr_find(learn)
# plotly.offline.plot(fig);訓練を行う関数 train_dl
引数: - learn: 学習器 - kwargs: 訓練を行う関数fit_one_cycleの任意のキーワード引数
https://docs.fast.ai/callback.schedule#Learner.fit_one_cycle 参照
train_dl
train_dl (learn, **kwargs)
fit_one_cycle法を用いて訓練を行う関数
#すべての顧客・製品ですると時間がかかる
#train_dl(learn, n_epoch = 30, lr_max =0.01, wd=2., cbs=ShowGraphCallback())#learn.export('all_demands.pkl')
#読み込み
learn = load_learner('all_demands.pkl')Plotlyで損出関数を描画する関数 plot_loss
引数: - learn: 学習器 - valid: テストデータも描画するときにTrue(既定値)
返り値: - fig: 損出関数のグラフ
深層学習を用いて予測を行う関数 predict_using_dl
引数: - learn:学習器 - df: 日付 (date)と需要 (deman)の列を含んだデータフレーム - future: 予測用の未来のデータを入れたデータフレーム - classification: 分類問題のとき True、それ以外のとき False
返値: - predict: 予測結果を入れたpandasのseriesオブジェクト - error: 予測の2乗誤差 - r2: 決定係数
predict_using_dl
predict_using_dl (learn, df, future, classification=False)
深層学習を用いた予測
predict_using_dl関数の使用例
# yhat, error, r2 = predict_using_dl(learn, train, future, classification=False)
# print("error=", error, r2)
#print(yhat)#hide_iinput
Image("../figure/predict_using_all_dl.png")
埋め込み層の描画関数 draw_embedding
引数:
- learn: 学習器(訓練済み)
- cust: 顧客を描画するときTrue, 製品を描画するとき False
- pca: 主成分分析で次元削減するときTrue、TSNEでするとき False
返値:
- fig: Plotlyの図オブジェクト
draw_embedding
draw_embedding (learn, cust=True, pca=True)
draw embedding
fig = draw_embedding(learn, cust=False, pca=False)
plotly.offline.plot(fig);
scikit learnのランダム森によって予測をする関数 random_forest
引数:
- df: 日付 (date)と需要 (deman)の列を含んだデータフレーム
- horizon: 検証データを作成するときの閾値の日付;この日付より後のデータは検証データになる。
- feature: 特徴ベクトルとして使用する列名のリスト; Noneのときには全ての列とする。
- classification: 分類問題のときTrue、回帰問題のときFalse
返値:
- forest: ランダム森のモデルオブジェクト
- importance: permutation_importanceによる特徴ベクトルの重要度の情報
random_forest
random_forest (df, horizon=None, feature=None, classification=False)
ランダム森による需要予測
random_forest関数の呼び出し例
# list(imp[imp.importance>0.01].features)
#feature = ['promo_1', 'Week', 'Month', 'Dayofyear', 'promo_0', 'Dayofweek']
#feature = list(df.columns[1:])
# feature = None
#forest, importance = random_forest(train, horizon="2020-10-01", feature=None, classification=False)重要度のデータフレームと図を返す関数 show_importance
引数: - importance: 重要度(順列重要度を random_forest関数で計算したときの返値として得られる.) - feature: 特徴ベクトルの名前のリスト - df: データフレーム;特徴ベクトルの元の列名を得るためだけに使用する.
返値: imp_df: 重要度を入れたデータフレーム fig: 重要度の棒グラフ
show_importance
show_importance (importance, feature, df)
#imp_df = show_importance(importance, feature=None, df=train)
#imp_df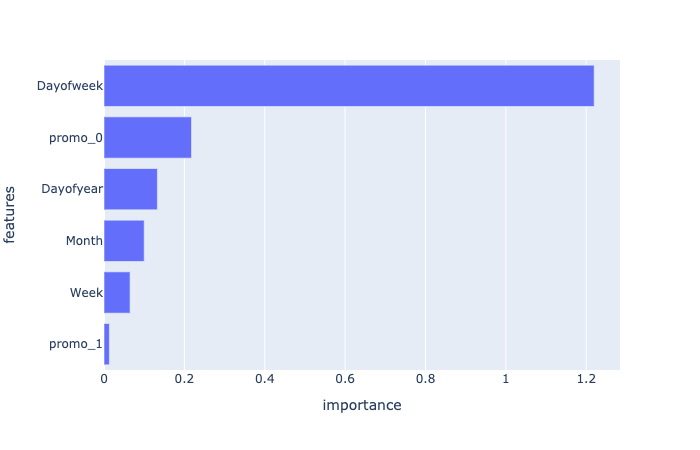
ランダム森による予測 predict_using_rf
引数: - df: 日付 (date)と需要 (deman)の列を含んだデータフレーム - future: 訓練用と予測用の未来のデータを入れたデータフレーム - forest: ランダム森のモデルオブジェクト - horizon: 予測期間
返値: - fig: 予測結果を入れた図オブジェクト - predict: 予測結果を入れた配列 - error: 予測の2乗誤差 - r2: 決定係数
predict_using_rf
predict_using_rf (df, future, forest, horizon=None, feature=None)
ランダム木を用いた予測
#yhat_rf, error_rf, r2 = predict_using_rf(train, future, forest, horizon="2020-10-01", feature=feature)
#print("error", error_rf, r2)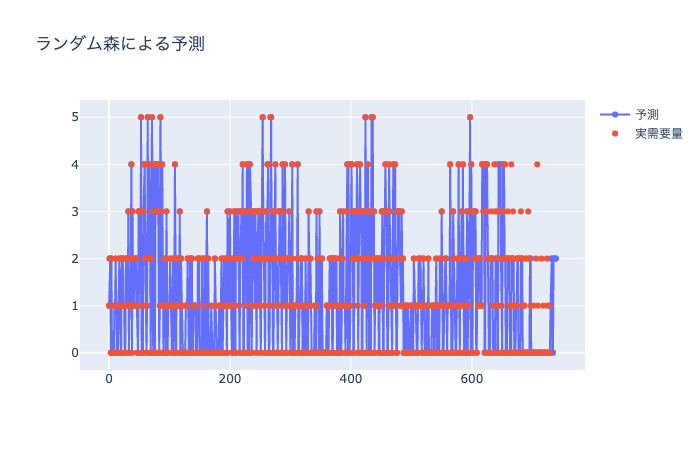
AutoMLで予測をする関数 automl
AutoMLパッケージPyCaretによる予測
引数:
- df: 日付 (date)と需要 (demand)の列を含んだデータフレーム
- horizon: 検証データを作成するときの閾値の日付;この日付より後のデータは検証データになる。Noneの場合には100日前からが検証データになる.
- num_bests: 最良モデルの選択数
- sort: 良い順に並べるときの評価尺度名(既定値は”R2”)
- model_name:
返値:
- best: 最良の予測をしたモデルオブジェクト
- result_df: 結果のデータフレーム
automl_pycaret
automl_pycaret (df, horizon=None, num_bests=5, sort='R2', model_name=None)
Prediction using pycaret regression models
automl関数の使用例
# horizon="2020/10/01"
# best, result_df = automl_pycaret(train, horizon, 5, model_name=None)#予測
# result = predict_model(best[0], future)
# result.head().T複数の製品・顧客に対して予測を行う関数(のサブ関数) automl_all_sub
サプライ・チェイン最適化のためには,すべての顧客と製品に対して一度に需要予測を行う必要がある.しかし,通常は顧客数,製品数ともに非常に多い場合には,計算時間が問題になる.顧客や製品に対するABC分析を事前に行い,A製品(A顧客)に対してだけ,需要予測を行うという経験的手法が従来使われていたが,ここではデータに基づいた手法を考える.
需要予測は,顧客・製品ごとに時系列データ(にプロモーション情報を付加したもの)を抽出し,AutoMLで複数の機械学習・統計分析モデルを適用して,最も良いものを使うことにする.評価尺度としては決定係数を使う.決定係数が負のものは平均を用いた単純な予測より当たらないことを意味する.
顧客・製品ごとに需要の合計量を被増加順に並べ,大きいものから順に予測を行っていく.一般に,zip分布にしたがう需要を想定すると,需要の合計が小さい場合には,どのような予測をしても当たらなくなる.複数の手法を試し,最も良い予測の決定係数が負のものが続く場合には,需要が小さすぎてこれ以上予測をしても無駄だと判断できる.したがって,決定係数が負のものが適当な数(たとえば10)より大きくなったら,予測をやめて,顧客・製品ごとの需要の平均値と標準偏差だけで管理するものとする.
引数:
- demand_df: 顧客 (cust)・製品 (prod) ごとの日付 (date)と需要 (deman)の列を含んだデータフレーム
- promo_df: 追加特徴(プロモーション)情報を含んだデータフレーム(オプション);予測期間に対しても追加情報を準備する必要がある. 予測期間内のデータが空 (NaN)の場合には,訓練データにも空 (NaN)のものがある必要がある.
- cust_list: 予測を行いたい顧客のリスト
- prod_list 予測を行うたい製品のリスト
- horizon: 検証データを作成するときの閾値の日付;この日付より後のデータは検証データになる.
- agg_period: 期間を表す文字列(例えば1日のときは”1d”)
- forecast_periods: 予測したい期間(既定値は1)
- threshold: 需要の予測誤差の幅を決めるためのパラメータ;外れる確率がthresholdになるように下限と上限を決める.
- max_neg_r2: 予測打ち切りのためのパラメータ;この回数だけ R2 が負になったら,それ以上予測する必要はないので, 終了する. ただし,cust_list と prod_listは需要量の降順になっているものと仮定する.
返値: - summary: 予測結果をまとめたデータフレーム;以下の列をもつ.
- cust: 顧客名
- prod: 製品名
- model: 最も良い予測モデル名
- rmse: 平均2乗誤差の平方根
- r2: 決定係数
- forecast: 未来の予測値
- lb: 予測誤差がlb以下になる確率がthresholdになるように設定
- ub: 予測誤差がub以上になる確率がthresholdになるように設定
automl_all_sub
automl_all_sub (demand_df, promo_df, cust_list, prod_list, horizon, agg_period='1d', forecast_periods=1, threshold=0.05, max_neg_r2=10)
複数の製品・顧客に対して予測を行う関数 automl_all
model 列には,最も良い(決定係数が1に近い)モデル名が保管されている.これを用いて,未来の予測をしたい場合には,そのモデルだけで予測をすれば良い.
予測値と実際の需要量が大きく外れた場合には,原因を探ったり,再予測を行ったりする必要がある.それには,予測誤差の下限と上限(lb,ub列)を用いれば良い.実際の運用ができるような,自動処理を行うシステムは,MLOpsと呼ばれる.
ここで開発したものは,MLOpsの基礎として使うことができる.
引数:
- demand_df: 顧客 (cust)・製品 (prod) ごとの日付 (date)と需要 (deman)の列を含んだデータフレーム
- promo_df: 追加特徴(プロモーション)情報を含んだデータフレーム(オプション);予測期間に対しても追加情報を準備する必要がある. 予測期間内のデータが空 (NaN)の場合には,訓練データにも空 (NaN)のものがある必要がある.
- horizon: 検証データを作成するときの閾値の日付;この日付より後のデータは検証データになる.
- agg_period: 期間を表す文字列(例えば1日のときは”1d”)
- forecast_periods: 予測したい期間(既定値は1)
- threshold: 需要の予測誤差の幅を決めるためのパラメータ;外れる確率がthresholdになるように下限と上限を決める.
- max_neg_r2: 予測打ち切りのためのパラメータ;この回数だけ \(R^2\) が負になったら,それ以上予測する必要はないので, 終了する. ただし,cust_list と prod_listは需要量の降順になっているものと仮定する.
- abc_threshold: ABC分析のための閾値のリスト(合計が1.0になっている必要がある.)
返値: - summary: 予測結果をまとめたデータフレーム;以下の列をもつ.(ただし予測を打ち切った行以降は model以降の列はNaNになる.)
- cust: 顧客名
- prod: 製品名
- mean: 平均需要量
- std: 需要の標準偏差
- rank: 需要の降順ランク
- abc: 需要量のABC分析の結果
- model: 最も良い予測モデル名
- rmse: 平均2乗誤差の平方根
- r2: 決定係数
- forecast: 未来の予測値
- lb: 予測誤差がlb以下になる確率がthresholdになるように設定
- ub: 予測誤差がub以上になる確率がthresholdになるように設定
automl_all
automl_all (demand_df, promo_df, horizon, agg_period='1d', forecast_periods=1, threshold=0.05, max_neg_r2=10, abc_threshold=[0.6, 0.2, 0.2])
automl_all関数の使用例
#summary = automl_all(demand_df, promo_df, horizon="2020/10/19", agg_period="1d", forecast_periods =10, threshold= 0.05, max_neg_r2 = 1)すべての顧客・需要の予測結果を用いて,予測を行い図を返す関数 predict_using_automl_all_fig
引数:
- demand_df: 顧客 (cust)・製品 (prod) ごとの日付 (date)と需要 (deman)の列を含んだデータフレーム
- promo_df: 追加特徴(プロモーション)情報を含んだデータフレーム(オプション);予測期間に対しても追加情報を準備する必要がある. 予測期間内のデータが空 (NaN)の場合には,訓練データにも空 (NaN)のものがある必要がある.
- summary: 予測結果をまとめたデータフレーム(automl_allの返値)
- customer: 顧客名
- product: 製品名
- agg_period: 期間を表す文字列(例えば1日のときは”1d”)
- forecast_periods: 予測したい期間(既定値は1)
返値: - forecast: 未来の予測値(リスト)
predict_using_automl_all_fig
predict_using_automl_all_fig (demand_df, promo_df, summary, customer, product, agg_period='1d', forecast_periods=10)
# agg_df,category = abc.abc_analysis_all(demand_df,[0.6, 0.2, 0.2])
# agg_df.reset_index(inplace=True)
# count = 0
# for row in agg_df.itertuples():
# fig, error, result = predict_using_automl_all_fig(demand_df, None, summary, row.cust, row.prod, agg_period='1d', forecast_periods=10)
# plotly.offline.plot(fig)
# count +=1
# if count>=10:
# breakすべての顧客・需要の予測結果を用いて,予測を行う関数 predict_using_automl_all
引数:
- demand_df: 顧客 (cust)・製品 (prod) ごとの日付 (date)と需要 (deman)の列を含んだデータフレーム
- promo_df: 追加特徴(プロモーション)情報を含んだデータフレーム(オプション);予測期間に対しても追加情報を準備する必要がある. 予測期間内のデータが空 (NaN)の場合には,訓練データにも空 (NaN)のものがある必要がある.
- summary: 予測結果をまとめたデータフレーム(automl_allの返値)
- customer: 顧客名
- product: 製品名
- agg_period: 期間を表す文字列(例えば1日のときは”1d”)
- forecast_periods: 予測したい期間(既定値は1)
返値: - forecast: 未来の予測値(リスト)
predict_using_automl_all
predict_using_automl_all (demand_df, promo_df, summary, customer, product, agg_period='1d', forecast_periods=10)
predict_using_automl_all関数の使用例
# customer = "長崎市"
# product = "D"
# customer ="熊本市"
# product ="H"
# predict_using_automl_all(demand_df, promo_df, summary, customer, product, agg_period='1d', forecast_periods=10)predict_using_automl
predict_using_automl (df, future, best, horizon=None)
AutoMLを用いた予測(回帰)
AutoMLによる予測関数 predict_using_automl
引数: - df: 日付 (date)と需要 (deman)の列を含んだデータフレーム - future: 訓練用と予測用の未来のデータを入れたデータフレーム - best: 予測モデルのオブジェクト - horizon: 予測期間
返値: - fig: 予測結果を入れた図オブジェクト - predict: 予測結果を入れた配列 - error: 予測の2乗誤差
predict_using_automl関数の使用例
#fig, error, result = predict_using_automl(df, future, best[0])
#plotly.offline.plot(fig);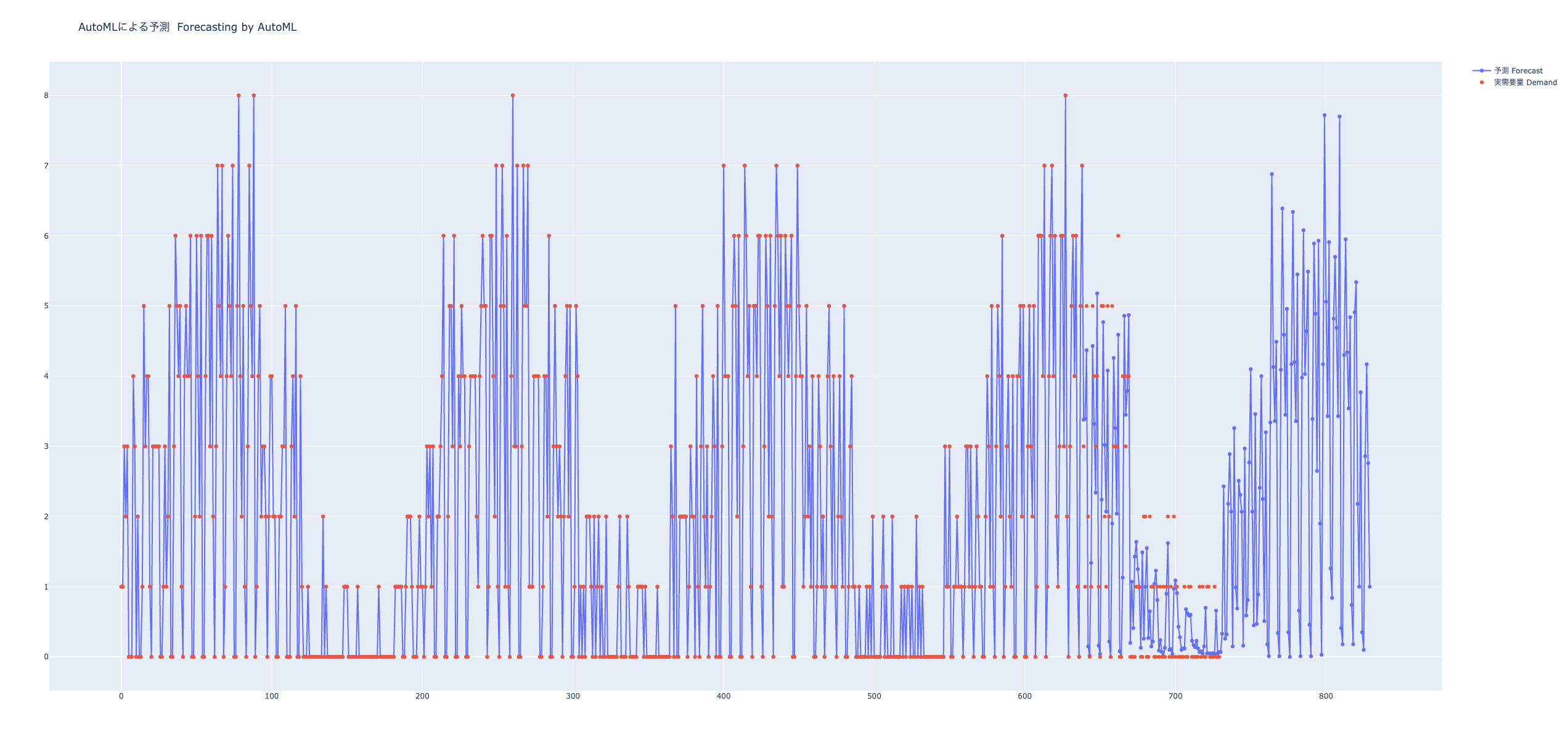
結果の可視化
- ‘residuals’ - Residuals Plot
- ‘error’ - Prediction Error Plot
- ‘cooks’ - Cooks Distance Plot
- ‘rfe’ - Recursive Feat. Selection
- ‘learning’ - Learning Curve
- ‘vc’ - Validation Curve
- ‘manifold’ - Manifold Learning
- ‘feature’ - Feature Importance
- ‘feature_all’ - Feature Importance (All)
- ‘parameter’ - Model Hyperparameter
- ‘tree’ - Decision Tree
#plot_model(best[0], "feature_all", save=True)分類モデル
#from pycaret.classification import * #分類関連の関数のインポート# #def automl(df, horizon=None, num_bests = 5, sort = "R2"):
# """
# Prediction using pycaret classification models
# """
# horizon = "2020/10/01"
# num_bests = 1
# sort = 'Accuracy'
# train_idx, valid_idx = prepare_index(df, horizon)
# ratio = len(train_idx)/(len(train_idx)+len(valid_idx))
# df["Week"] = df.Week.astype(int)
# df["demand"] = df.demand.astype('category')
# #df["demand"] = df.demand.astype(int)
# reg = setup(df, target = 'demand', session_id=123, data_split_shuffle=False, fold_strategy= 'timeseries', fold=2, train_size=ratio, silent=True, verbose=False)
# best = compare_models(n_select=num_bests, sort = sort, cross_validation=False)
# result_df = pull()
# #return best, result_df# #検証データに対する予測
# result = predict_model(best)
# #誤差の計算
# dem = result.demand.astype(int)
# #error_ = ((result.Label - result.demand)**2).mean()
# error_ = ((result.Label - dem)**2).mean()
# #実需要量のプロット
# trace2 = go.Scatter(
# x = df.index,
# y = df.demand,
# mode = 'markers',
# name ="実需要量 Demand"
# )
# #訓練+未来のデータに対する予測
# result = predict_model(best, future)
# #予測プロット
# trace1 = go.Scatter(
# x = result.index,
# y = result.Label,
# mode = 'markers + lines',
# name = "予測 Forecast"
# )
# data = [trace1, trace2]
# layout = go.Layout(
# title ="AutoMLによる予測 Forecasting by AutoML",
# )
# fig = go.Figure(data, layout)
# #return fig, error_, result
# plotly.offline.plot(fig);結果の可視化
#plot_model(best, plot = 'feature', verbose=True)
#fig_param = plot_model(best, plot = 'parameter')
#interpret_model(best, plot = 'correlation')
#plot_model(best, plot = 'error')#plot_model(best, plot = 'learning')#plot_model(best, plot = 'cooks')需要の集約
上では、顧客ごとに需要予測を行なった。ここでは、倉庫(配送センター、流通センター)ごとの予測や、工場ごとの予測について考える。
そのためには、ロジスティック・ネットワーク設計モデルで製品の流れを最適化した結果を用いる必要がある。
最適化した結果はflow.csvに保存されているので、そこから生成されたデータフレーム flow_df と需要データフレーム demand_df を入れると、 地点(工場、倉庫)ごとに集約された需要量を返す関数を準備する。
需要を地点ごとに集約する関数 aggregate_demand
引数: - demand_df : 需要データ - flow_df : 製品のフローを保管したデータ
返値: - aggregated_demand_df : 地点(工場、倉庫)と製品ごとに集約された需要データ - G: 製品をキーとし、フロー量を枝上に保管したグラフオブジェクト - Prod: 製品のリスト
aggregate_demand
aggregate_demand (demand_df, flow_df)
最適化された製品フローデータと需要データから、地点(工場、倉庫)ごとの集約された需要量を計算する関数
aggregate_demand関数の使用例
demand_df = pd.read_csv(folder+"demand.csv", index_col=0)
flow_df = pd.read_csv(folder+"flow.csv", index_col=0)
agg_demand_df, G, Prod = aggregate_demand(demand_df, flow_df)
agg_demand_df.head()| date | cust | prod | demand | |
|---|---|---|---|---|
| 0 | 2019-01-01 | DC_さいたま市 | A | 286.0 |
| 1 | 2019-01-01 | Plnt_Odawara | A | 337.0 |
| 2 | 2019-01-01 | DC_さいたま市 | B | 278.0 |
| 3 | 2019-01-01 | Plnt_Odawara | B | 327.0 |
| 4 | 2019-01-01 | DC_さいたま市 | C | 108.0 |
#グラフ G の描画
p ="B"
pos = G[p].layout()
nx.draw(G[p], pos=pos, node_color="Blue", node_size=10)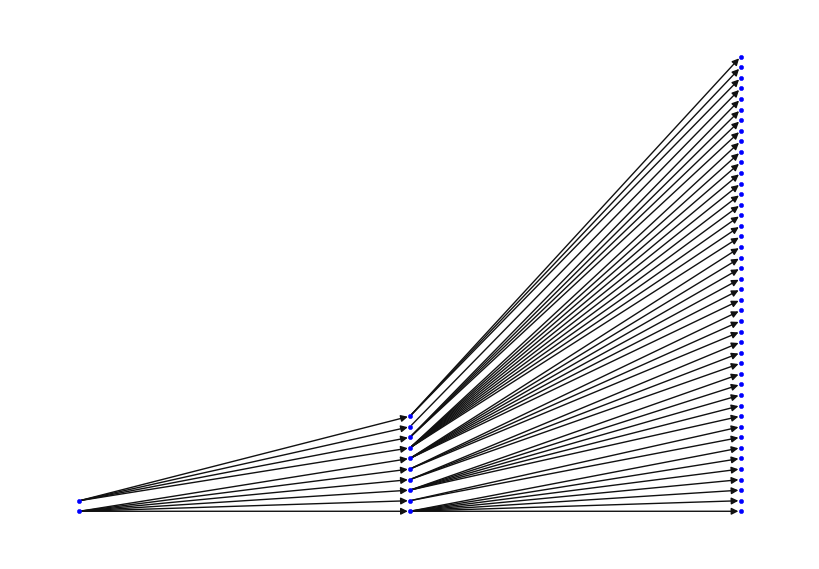
集約した需要をもとに安全在庫量を計算
単一ソース供給でない地点に対しては、安全在庫量を計算するための方法が確立されていない。 ここでは、異なるリード時間をもつ複数の地点から供給される場合には、ロジスティック・ネットワーク設計問題で求めた製品の年間フロー量をもとに、以下の方法で計算するものとする。
地点 \(j\) が、複数の地点 \(i (i \in S_j)\) からフロー量 \(f_{ij}\) で供給を受けているものとする。供給地点をフロー量の大きさに応じてランダムに選ぶものと仮定し、その確率を \(\lambda_{ij}\) とする。
\[ \lambda_{ij} = \frac{f_{ij}}{\sum_{i \in S_j} f_{ij}} \]
地点 \(i\) から地点 \(j\) へのリード時間を \(L'_{ij}\) としたとき、地点 \(j\) へのリード時間(確率変数) \(L_j\) は、確率 \(\lambda_{ij}\) で値 \(L'_{ij}\) をとる離散確率分布になる。
\(L_j\) の期待値 \(E[L_j]\) と分散 \(Var(L_j)\) は、scipyモジュールを使えば簡単に計算できる。 これらの値を使えば、平均 \(\mu\)、標準偏差 \(\sigma\) の正規分布にしたがう需要に対するリード時間内の需要量 \(D\) の期待値 \(E[D]\) と分散 \(Var(D)\) は、以下のように計算できる。
\[ E[D] = \mu E[L_j] \]
\[ Var(D) = \sigma E[L_j] + \mu^2 Var(L_j) \]
導出については、「はじめての確率論」(近代科学社)pp.92-94を参照されたい。
安全在庫量は、安全在庫係数を \(z\) としたとき、以下のように計算される。
\[ E[D] + z \sqrt{ Var(D) } \]
集約した需要をもとに安全在庫量を計算する関数 compute_safety_stock
引数: - demand_df : 需要データ - agg_demand_df : 地点(工場、倉庫)と製品ごとに集約された需要データ - trans_df : 地点間のリード時間を保管したデータ - plnt_prod_df : 工場ごとの製品の生産リード時間を保管したデータ - Prod: 製品のリスト - G: 製品をキーとし、フロー量を枝上に保管したグラフオブジェクト
返値: - safety_df : 地点・製品ごとの安全在庫量を保管したデータ
compute_safety_stock
compute_safety_stock (demand_df, agg_demand_df, trans_df, plnt_prod_df, Prod, G)
倉庫・工場・顧客に対する安全在庫量の計算
compute_safety_stock関数の使用例
#trans_df = pd.read_csv(folder + "trans.csv", index_col=0)
#plnt_prod_df = pd.read_csv(folder + "Plnt-Prod.csv", index_col=0)
#safety_df = compute_safety_stock(demand_df, agg_demand_df, trans_df, plnt_prod_df, Prod, G)
# safety_df.to_csv(folder+"safety.csv")在庫の比較関数 inventory_comparison
inventory_comparison
inventory_comparison (df:pandas.core.frame.DataFrame, predict:pandas.core.frame.DataFrame, service_level:float=0.95, LT:int=0)
予測クラス Forecast
上の諸関数を用いて予測をするためのクラスを設計する.
Forecast
Forecast (cust_df:pandas.core.frame.DataFrame, prod_df:pandas.core.frame.DataFrame, demand_df:pandas.core.frame.DataFrame, promo_df:Optional[pandas.core.frame.DataFrame]=None, time_serie s_dfs:Dict[Tuple[str,str],pandas.core.frame.DataFrame]=None, agg_period:str='1d', forecast_periods:int=1, lagged_regressors:List[str]=[], future_regressors:List[str]=[], events:List[str]=[], country:Optional[str]=None)
Usage docs: https://docs.pydantic.dev/2.6/concepts/models/
A base class for creating Pydantic models.
Attributes: class_vars: The names of classvars defined on the model. private_attributes: Metadata about the private attributes of the model. signature: The signature for instantiating the model.
__pydantic_complete__: Whether model building is completed, or if there are still undefined fields.
__pydantic_core_schema__: The pydantic-core schema used to build the SchemaValidator and SchemaSerializer.
__pydantic_custom_init__: Whether the model has a custom `__init__` function.
__pydantic_decorators__: Metadata containing the decorators defined on the model.
This replaces `Model.__validators__` and `Model.__root_validators__` from Pydantic V1.
__pydantic_generic_metadata__: Metadata for generic models; contains data used for a similar purpose to
__args__, __origin__, __parameters__ in typing-module generics. May eventually be replaced by these.
__pydantic_parent_namespace__: Parent namespace of the model, used for automatic rebuilding of models.
__pydantic_post_init__: The name of the post-init method for the model, if defined.
__pydantic_root_model__: Whether the model is a `RootModel`.
__pydantic_serializer__: The pydantic-core SchemaSerializer used to dump instances of the model.
__pydantic_validator__: The pydantic-core SchemaValidator used to validate instances of the model.
__pydantic_extra__: An instance attribute with the values of extra fields from validation when
`model_config['extra'] == 'allow'`.
__pydantic_fields_set__: An instance attribute with the names of fields explicitly set.
__pydantic_private__: Instance attribute with the values of private attributes set on the model instance.cust_df = pd.read_csv(folder+"cust.csv")
prod_df = pd.read_csv(folder+"prod.csv")
promo_df = pd.read_csv(folder+"promo.csv", index_col=0)
demand_df = pd.read_csv(folder+"demand_with_promo_all.csv", index_col=0)
forecast = Forecast(cust_df = cust_df, prod_df = prod_df, demand_df = demand_df, promo_df=promo_df,
agg_period="1d", forecast_periods =100,
future_regressors=["promo_0", "promo_1"],
country ="JP") # https://python-holidays.readthedocs.io/en/latest/
time_series_dfs = forecast.prepare_dfs()
c = "仙台市"
p = "A"
df = time_series_dfs[p,c] #サンプルデータフレームの保管(関数のテストで用いる)
# df.to_csv(folder+"a_demand.csv")
# #DL
# predict, error, r2 = forecast.deep_learning(p,c)
# print("DL=", error, r2)
#AUTOML
predict, error, r2, best_model, best_name, fig, best, result_df = forecast.automl(p,c)
print("AUTO ML", error, r2, best_model, best_name)
# predict, y = forecast.holt_winter(p,c,seasonal_periods=7,
# trend="add",
# seasonal="multiplicative",
# initialization_method="estimated")
# y.plot()
# predict.plot();
#plotly.offline.plot(fig);
#Forecastクラスで予測をしたあとで用いる.
service_level = 0.99
LT = 2
inv_fig, simulation_table = inventory_comparison(df, predict, service_level, LT)
#plotly.offline.plot(inv_fig);| Model | MAE | MSE | RMSE | R2 | RMSLE | MAPE | TT (Sec) | |
|---|---|---|---|---|---|---|---|---|
| gbr | Gradient Boosting Regressor | 0.5478 | 0.4750 | 0.6892 | 0.9219 | 0.2050 | 0.2187 | 0.0700 |
| et | Extra Trees Regressor | 0.4636 | 0.6023 | 0.7760 | 0.9009 | 0.1404 | 0.1666 | 0.0400 |
| rf | Random Forest Regressor | 0.6189 | 1.1159 | 1.0564 | 0.8164 | 0.1910 | 0.2266 | 0.0600 |
| dt | Decision Tree Regressor | 0.8378 | 4.3514 | 2.0860 | 0.2842 | 0.2429 | 0.1582 | 0.0100 |
AUTO ML 0.6892 0.9219 gbr Gradient Boosting Regressor# model, train_df, future_df = forecast.bayes_dl(p,c,
# # Disable trend changepoints
# n_changepoints=0,
# growth ="off", # off or linear or discountinuous
# # Disable seasonality components, except yearly
# yearly_seasonality=True,
# weekly_seasonality=True,
# daily_seasonality=False,
# seasonality_mode = "additive", #additive* or multiplicative
# quantiles = [0.1, 0.9],
# )
# metrics = model.fit(train_df)
# print(metrics)
# predict = model.predict(future_df)
# #model.plot_components(predict)
# #model.plot(predict)
# predict.head()Test Pycaret Series
# from pycaret.time_series import TSForecastingExperiment
# exp = TSForecastingExperiment()
# model, train_df, future_df = forecast.bayes_dl(p,c)
# future_df.fillna(0, inplace=True)
# exp.setup(future_df, target ="y", fh = forecast.forecast_periods, session_id = 123)
#exp.setup(time_series_dfs[p,c], target ="y", fh = forecast.forecast_periods, session_id = 123)# check statistical tests on original data
#exp.check_stats()
#best = exp.compare_models()#exp.plot_model(best, plot="cv")
#predict = exp.predict_model(best, fh=100)
#exp.plot_model(best) #plot = 'diagnostics')#new_future_df = add_datepart(future, "ds", drop=False, time=False)# model = NeuralProphet( n_changepoints=0,
# growth ="off", # off or linear or discountinuous
# # Disable seasonality components, except yearly
# yearly_seasonality=True,
# weekly_seasonality=True,
# daily_seasonality=False,
# seasonality_mode = "additive", #additive* or multiplicative
# quantiles = [0.1, 0.9],
# future_regressors_model ="neural_nets",
# future_regressors_d_hidden = 3,
# future_regressors_num_hidden_layers = 10,
# )
# for r in new_future_df.columns[2:10]:
# model.add_future_regressor(r, mode="additive")
# new_future_df.T# train_df = new_future_df[ new_future_df.y != None ]
# metrics = model.fit(train_df.iloc[:,:10])
# print(metrics)#predict = model.predict(future)
#model.plot_components(predict)
#model.plot(predict)