ロジスティクス・ネットワーク設計システム MELOS
ロジスティクス・ネットワーク設計システム MEta Logistic network Optimization System
簡易システムビデオ
MELOS (MEta Logistic Optimization System)
MEta Logistic network Optimization System-GF (Green FIeld)
はじめに
ここでは,ロジスティクス・ネットワーク設計問題に対する包括的モデルを示す. モデルの目的は,単位期間(通常は年)ベースのデータをもとに, ロジスティクス・ネットワークの形状を決めることにある. モデルを求解することによって得られるのは,倉庫の設置の是非, 地点間別の各製品の単位期間内の総輸送量, 工場別の各製品の単位期間内の総生産量である.
ロジスティクス・ネットワーク設計モデルでは, 以下の意思決定項目に対する最適化を同時に行う.
- 各製品をどの工場でどれだけ生産するか?
- 各製品をどの倉庫(配送センターや中継拠点の総称)で保管するか?
- 各顧客群の各製品の需要を,どの地点から運ぶか?
- 倉庫をどこに新設するか?(または移転,閉鎖するか?)
- 複数の倉庫の候補地点からどれを選択するか?
このような意思決定は,単に現状のロジスティクス・ネットワーク の見直しを行う場合だけでなく,以下の状況においても有効に用いられる.
- 吸収・合併の後のロジスティクス・ネットワークの再編成
- 新製品投入時の意思決定(どこで製造して,どのような流通チャネルで流すか)
- ロジスティクスにおける戦略的提携(ロジスティクス・パートナーシップ)
例題
ここで用いるサンプルデータは, データ生成モジュールのgenerate_cust, generate_prod, generate_demandなどの諸関数を用いて生成したものである.
以下,順に説明する.
顧客データ
品が最終的に消費される場所を顧客(customer)とよぶ. 顧客は,対象となるシステムに依存して,小売店であったり個々の家庭であったりする. モデルとして扱う場合には,同じ施設からサービスされると考えられる顧客の集まりを 1つの顧客に集約することができる. ここでは,個々の顧客を同じサプライ・チェインでサービス を行っても差し支えない程度に集約したものを顧客群(customer group)とよぶこともあるが,以下では単に顧客と呼ぶ.
通常は,需要の大きい顧客や特殊なサービスを要求する顧客は1つの顧客として扱い, 残りの顧客を地区ごとに集約して扱うことが多い. これは,同じ地区に属する顧客への配送は,(大口や特殊な顧客以外は) 同一のデポから行われる場合が多いことに起因する. 個々の顧客の数は数万から数十万におよぶこともあるが, 集約後の顧客群の数は,多くても数百になるようにする.
顧客群に集約するための簡便法として郵便番号を用いる方法もあるが, できれば1つの顧客群に含まれる顧客数および需要量が,なるべくバランスするように することが望ましい. ここでは,幾つかのクラスタリング手法 (Weizfeld法, \(k\)-means法, 階層的クラスタリング法, \(k\)-メディアン法) を用いる.
例題で用いる顧客データの列は, 名前 (name) と緯度・経度 (lat, lon; latitude, longitudeの略) である.
cust_df = pd.read_csv(folder + "cust.csv", index_col=0)
cust_df.head()| name | lat | lon | |
|---|---|---|---|
| id | |||
| 1 | 札幌市 | 43.06417 | 141.34694 |
| 2 | 青森市 | 40.82444 | 140.74000 |
| 3 | 盛岡市 | 39.70361 | 141.15250 |
| 4 | 仙台市 | 38.26889 | 140.87194 |
| 5 | 秋田市 | 39.71861 | 140.10250 |
製品データ
ロジスティクス・ネットワーク内を流れるものを製品(product)とよぶ. 製品の種類は,対象とするロジスティクス・システムにもよるが,通常は膨大なものになるが, ストラテジックレベルの意思決定モデルを扱う場合には,通常同じ特性をもつ製品を集約して扱う. 製品を集約したものを,個々の製品と区別するために製品(product group)とよぶこともある. 通常,製品の数が数十程度になるように集約する. また,ABC分析をして,影響の少ない製品を除いて最適化を行うこともある.
製品データは,以下の列をもつが,ロジスティクス・ネットワーク設計モデルで使うのは,名称 (name)と重量 (weight)だけである.
- name: 製品の名称
- weight: 製品の重量 (単位はkg)
- volume: 製品の容量 (単位は 𝑚3 )
- cust_value: 顧客上での製品の価値
- dc_value: 倉庫上での製品の価値
- plnt_value: 工場における製品の価値
- fixed_cost: 製品を生産する際の段取り(固定)費用
prod_df = pd.read_csv(folder + "prod.csv", index_col=0)
prod_df.head()| name | weight | volume | cust_value | dc_value | plnt_value | fixed_cost | |
|---|---|---|---|---|---|---|---|
| 0 | A | 2 | 0 | 7 | 1 | 1 | 14 |
| 1 | B | 5 | 0 | 5 | 1 | 1 | 14 |
| 2 | C | 1 | 0 | 5 | 1 | 1 | 19 |
| 3 | D | 3 | 0 | 5 | 1 | 1 | 17 |
| 4 | E | 1 | 0 | 10 | 1 | 1 | 18 |
倉庫データ
最終需要地点および供給地点以外の場所で,かつ製品の製造・加工を行わない地点を総称して 倉庫(warehouse)とよぶことにする. 実際には,倉庫は流通センター(DC: Distribution Centerの略),デポ,クロスドッキング地点,港,空港,ハブなど様々な形態をとる.
倉庫の役割と機能には,以下のものが考えられる.
調達(購入)の規模の経済性のため. 大量購入に伴う割引が行われるとき,大量に購入した製品を一時的に保管しておく際に,倉庫の保管機能が用いられる.
混載による規模の経済性のため.複数の小売店(スーパーなど)で消費される製品を, 直接製造業者(メーカー)から輸送すると,小ロットの輸送のため費用が増大する. メーカーから車立て輸送を行うためには,複数の小売店の需要をあわせる必要があるが, そのための中継地点として倉庫の仕分け機能が用いられる. メーカーから運ばれた複数の製品は,倉庫で方面別に仕分けされて,小売店に運ばれる. この際,複数の製品を混載して輸送するので,やはり小ロット輸送による費用の増大を避けることができる. この仕分け機能に特化した倉庫をクロスドッキング地点(cross docking point)とよぶ. クロスドッキング地点は,保管機能をもたず,メーカーから小売店が発注した量と同じ量を受け取り, 即座に仕分けして小売店に輸送する.
リスク共同管理効果を得るため. 複数の小売店の在庫を,集約して倉庫に保管することによって,安全在庫量を減らすことができる.これをリスク共同管理(risk pooling)効果とよぶ. この場合には,倉庫は,リスク共同管理によってサプライ・チェイン全体での在庫を減らすために用いられる.
顧客へのサービスレベル向上のため. たとえば,コンビニエンスストアの配送センターは,弁当が約\(3\)時間以内で配達可能なように設置される. これによって,\(1\)日に数回の弁当の配送が可能になり,顧客に出来たての弁当を届けることが可能になる. このように,倉庫は小売店(コンビニエンスストア)へのリード時間を減少させるために用いられる.
単一ソース条件. 顧客(特に小売店)に対して,複数の倉庫からの配送を行うことを許さないという条件が付加されることがある. これは,荷捌き場の制限や,荷物の受け入れを複数回行う手間を省くためであるが,そのためには,複数のメーカーの製品を倉庫で積み替えて 運ぶことが必要になる.
製品に付加価値をつけるため. 最終製品への分化を,なるべくサプライ・チェインの下流で行うことによって, 顧客サービスを向上させ,安全在庫を減少させることができる. これを遅延差別化(delayed differentiation, postponement)とよぶ. 遅延差別化の方法として, 工場で最終製品まで製造してまうのではなく,顧客に近い倉庫で,製造の最終工程を行うことがあげられる. たとえば,値札やラベルを付けたり,簡単な加工を行うことが代表例である.
倉庫データは,倉庫の配置可能地点を表し,以下の列をもつ.
- name: 倉庫名称
- lb: 容量下限
- ub: 容量上限
- fc: 固定費用
- vc: 変動費用
- lat: 緯度
- lon: 経度
dc_df = pd.read_csv(folder + "DC.csv", index_col=0)
dc_df.head()| name | lb | ub | fc | vc | lat | lon | |
|---|---|---|---|---|---|---|---|
| 0 | 札幌市 | 0.0 | 501136.2 | 10037 | 0.432510 | 43.06417 | 141.34694 |
| 1 | 青森市 | 0.0 | 501136.2 | 10235 | 0.414573 | 40.82444 | 140.74000 |
| 2 | 盛岡市 | 0.0 | 501136.2 | 10908 | 0.414802 | 39.70361 | 141.15250 |
| 3 | 仙台市 | 0.0 | 501136.2 | 10072 | 0.136525 | 38.26889 | 140.87194 |
| 4 | 秋田市 | 0.0 | 501136.2 | 10767 | 0.029622 | 39.71861 | 140.10250 |
工場データ
製品の製造・加工する地点を総称して工場(plant)とよぶ. 実際には,工場は生産工場,部品工場,流通加工を行う倉庫など様々な形態をとる.
工場における製品の生産量上限は,別途定義するので,工場は名称(name)と緯度・経度情報 (lat,lon) だけをもつ.
plnt_df = pd.read_csv(folder + "Plnt.csv", index_col=0)
plnt_df.head()| name | lat | lon | |
|---|---|---|---|
| 0 | Odawara | 35.284982 | 139.196133 |
| 1 | Osaka | 34.563101 | 135.415129 |
| 2 | Chiba | 35.543452 | 140.113908 |
需要データ
ロジスティクス・ネットワーク設計モデルでは,各顧客・製品に対する計画期間内の総需要量の情報が必要になる. 通常,計画期間は1年とし,年間の総需要を入力とする.これは,日々の需要を記録した需要データから計算される.
需要データは,以下の列をもつ.
- date: 日付
- cust: 顧客名
- prod: 製品名
- demand: 需要量
demand_df = pd.read_csv(folder + "demand.csv", index_col=0)
demand_df.head()| date | cust | prod | demand | sales | |
|---|---|---|---|---|---|
| index | |||||
| 0 | 2019-01-01 | 札幌市 | A | 10 | 10 |
| 1 | 2019-01-01 | 札幌市 | B | 10 | 10 |
| 2 | 2019-01-01 | 札幌市 | C | 3 | 3 |
| 3 | 2019-01-01 | 札幌市 | D | 0 | 0 |
| 4 | 2019-01-01 | 札幌市 | E | 37 | 37 |
生産データ
計画期間内における工場における製品の生産量には上限がある.これを定義するのが生産データである. 使用する列は,工場名 (plnt),製品名 (prod),生産量上限 (ub)だけである.
plnt_prod_df = pd.read_csv(folder + "Plnt-Prod.csv", index_col=0)
plnt_prod_df.head()| plnt | prod | ub | lead_time | |
|---|---|---|---|---|
| 0 | Osaka | D | 813 | 28 |
| 1 | Osaka | A | 18026 | 29 |
| 2 | Osaka | E | 77704 | 25 |
| 3 | Osaka | J | 52907 | 26 |
| 4 | Osaka | G | 15774 | 28 |
連続施設配置問題
平面上に施設が配置可能と仮定した施設問題に対する近似解法を考える。
施設数が1つの場合には、Weiszfeld法と呼ばれる反復法で近似解が得られることが知られている。 複数施設に対しては、k-means法と似た反復解法が考えられる。ここでは、重み付き複数施設配置問題に対するWeiszfeld法を構築する。
以下では、1つの施設を選択するためのWeiszfeld法について解説する。
各顧客 \(i\) は平面上に分布しているものとし,その座標を \((X_i,Y_i)\) とする. 顧客は重み \(w_i\) をもち,目的関数は施設と顧客の間の距離に重みを乗じたものの和とする. 顧客と施設間の距離は \(\ell_p\) ノルム(\(1 \leq p\))を用いて計算されるものとする. 東京都市圏の道路ネットワークでは \(p \approx 1.8901\) と推定されており, 実務的には Euclidノルム(\(p=2\))に迂回係数(\(1.3\) 程度) を乗じたものを使う場合が多い.
顧客の集合 \(I\) に対して,単一の倉庫の配置地点 \((X,Y)\) を決定する問題は, \[ f(X,Y) = \sum_{i \in I} w_i \left\{ (X-X_i)^p +(Y-Y_i)^p \right\}^{1/p} \] を最小にする \((X,Y) \in \mathbf{R}^2\) を求める問題になる. これは,以下の Weiszfeld法を拡張した解法を用いることによって容易に求解できる.
上の関数は凸関数であるので, \((X,Y)\) が最適解である必要十分条件は,\((X,Y)\) が \[ \frac{\partial f(X,Y)}{\partial X} =0 \] および \[ \frac{\partial f(X,Y)}{\partial Y} =0 \] を満たすことである. \[ \frac{\partial f(X,Y)}{\partial X} = \sum_{i \in I} w_i (X-X_i) \frac{ |X-X_i|^{p-2}}{\left\{ (X-X_i)^p +(Y-Y_i)^p \right\}^{(p-1)/p} } =0 \] は陽的に解くことができないが, 以下の \(X\) に対する繰り返し式を示唆している. \[ X^{(q+1)}= \frac{ \sum_{i \in I} w_i |X^{(q)}-X_i|^{p-2} X_i/ \left\{ (X^{(q)}-X_i)^p +(Y^{(q)}-Y_i)^p \right\}^{(p-1)/p} }{ \sum_{i \in I} w_i |X^{(q)}-X_i|^{p-2}/ \left\{ (X^{(q)}-X_i)^p +(Y^{(q)}-Y_i)^p \right\}^{(p-1)/p} } \]
\(Y\) についても同様の式を導くことができる.
これらの式を利用した解法は,一般に不動点アルゴリズムとよばれ, \(1 \leq p \leq 2\) のとき大域的最適解に収束する.
Weiszfeld法を実行する関数 weiszfeld_numpy と weiszfeld
施設数が1つの場合には、Weiszfeld法と呼ばれる反復法で近似解が得られることが知られている。 複数施設に対しては、\(k\)-means法と似た反復解法が考えられる。ここでは、重み付き複数施設配置問題に対するWeiszfeld法を構築する。
移動距離は大圏距離distanceを用いる。これはgeopyから読み込んであると仮定する。 例題においては,顧客の重みは、年間の製品需要量に製品の重量を乗じたものとする。
引数: - cust_df : 顧客データフレーム;緯度経度情報を利用する。 - weight : 顧客の重み;重み付きの大圏距離の和を最小化するものとする。 - num_of_facilities : 平面上に配置する施設の数を指定する。 - epsilon : 誤差上限 - max_iter : 反復回数の上限 - seed: 乱数の種 - X0 : 施設の緯度のリストの初期値 - Y0 : 施設の経度のリストの初期値
返値: - X : 施設の緯度のリスト - Y : 施設の経度のリスト - partition : 顧客の割り当てられた施設の番号を格納したリスト - cost: 費用(重み付きの距離の総和)
weiszfeld_numpyはNumPyを用いた実装であり, weiszfeldは通常の実装である.
weiszfeld_numpy
weiszfeld_numpy (cust_df, weight, num_of_facilities, epsilon=0.0001, max_iter=1000, seed=None, X0=None, Y0=None)
Weiszfeld法; 複数施設の連続施設配置問題の近似解法 (NumPy version)
weiszfeld
weiszfeld (cust_df, weight, num_of_facilities, epsilon=0.0001, max_iter=1000, seed=None, X0=None, Y0=None)
Weiszfeld法; 複数施設の連続施設配置問題の近似解法
weiszfeld関数の使用例
cust_df = pd.read_csv(folder + "cust.csv", index_col=0) #read customer data for using Lat/Lng
cust_df.head()| name | lat | lon | |
|---|---|---|---|
| id | |||
| 1 | 札幌市 | 43.06417 | 141.34694 |
| 2 | 青森市 | 40.82444 | 140.74000 |
| 3 | 盛岡市 | 39.70361 | 141.15250 |
| 4 | 仙台市 | 38.26889 | 140.87194 |
| 5 | 秋田市 | 39.71861 | 140.10250 |
prod_df = pd.read_csv(folder + "prod.csv", index_col=0) #read product data (for using weight)
prod_df.head()| name | weight | volume | cust_value | dc_value | plnt_value | fixed_cost | |
|---|---|---|---|---|---|---|---|
| 0 | A | 2 | 0 | 7 | 1 | 1 | 14 |
| 1 | B | 5 | 0 | 5 | 1 | 1 | 14 |
| 2 | C | 1 | 0 | 5 | 1 | 1 | 19 |
| 3 | D | 3 | 0 | 5 | 1 | 1 | 17 |
| 4 | E | 1 | 0 | 10 | 1 | 1 | 18 |
total_demand = pd.read_csv(folder + "total_demand.csv")
total_demand.head()| Unnamed: 0 | prod | cust | demand | |
|---|---|---|---|---|
| 0 | 0 | A | さいたま市 | 93.255495 |
| 1 | 1 | A | 京都市 | 165.453297 |
| 2 | 2 | A | 仙台市 | 62.170330 |
| 3 | 3 | A | 佐賀市 | 907.486264 |
| 4 | 4 | A | 前橋市 | 85.233516 |
weight_of_prod ={p:w for (p,w) in zip(prod_df.name, prod_df.weight) } #prepare weight dic.
weight_of_cust = defaultdict(int)
for row in total_demand.itertuples():
weight_of_cust[row.cust] += weight_of_prod[row.prod]*row.demand
#weight = [weight_of_cust[row.name] for row in cust_df.itertuples()]
weight = [weight_of_cust[i] for i in weight_of_cust]
# 関数呼び出し
X, Y, partition, cost = weiszfeld(cust_df, weight, num_of_facilities = 10, epsilon=0.0001, max_iter = 10, seed=1)
print(cost)
# X, Y, partition, cost = weiszfeld(cust_df, weight, num_of_facilities = 10, epsilon=0.0001, max_iter = 10, seed=1, X0=X, Y0=Y)
# print(cost)
#X, Y, partition, cost = weiszfeld_numpy(cust_df, weight, num_of_facilities = 10, epsilon=0.0001, max_iter = 10, seed=1)
#print(cost)
# X, Y, partition, cost = weiszfeld_numpy(cust_df, weight, num_of_facilities = 10, epsilon=0.0001, max_iter = 10, seed=123, X0=X, Y0=Y)
# print(cost)11030261.63674016反復Weiszfeld法を実行する関数 repeated_weiszfeld
Weiszfeld法を一定回数初期解を変えながら実行し,最も良い結果を返す関数
引数: - cust_df : 顧客データフレーム;緯度経度情報を利用する。 - weight : 顧客の重み;重み付きの大圏距離の和を最小化するものとする。 - num_of_facilities : 平面上に配置する施設の数を指定する。 - epsilon : 誤差上限 - max_iter : 反復回数の上限 - numpy: NumPyを用いる場合にTrue - seed: 乱数の種
返値: - X : 施設の緯度のリスト - Y : 施設の経度のリスト - partition : 顧客の割り当てられた施設の番号を格納したリスト - cost: 費用(重み付きの距離の総和)
repeated_weiszfeld
repeated_weiszfeld (cust_df, weight, num_of_facilities, epsilon=0.0001, max_iter=1, numpy=True, seed=None)
TODO: Multicore (threading)で高速化
X, Y, partition, cost = repeated_weiszfeld(cust_df, weight,
num_of_facilities = 10, epsilon=0.0001, max_iter = 30, numpy=False, seed=2)
print(cost)CPU times: user 2 µs, sys: 1e+03 ns, total: 3 µs
Wall time: 6.91 µs
9674288.59942924連続施設配置の可視化関数 show_optimized_continuous_network
引数: - cust_df : 顧客データフレーム - X : 施設の緯度のリスト - Y : 施設の経度のリスト - partition : 顧客の割り当てられた施設の番号を格納したリスト - weight: 顧客の重み(この大きさにあわせて点を描画する.)
返値: - fig: Plotlyの図オブジェクト
show_optimized_continuous_network
show_optimized_continuous_network (cust_df, X, Y, partition, weight=None)
連続施設配置の可視化関数
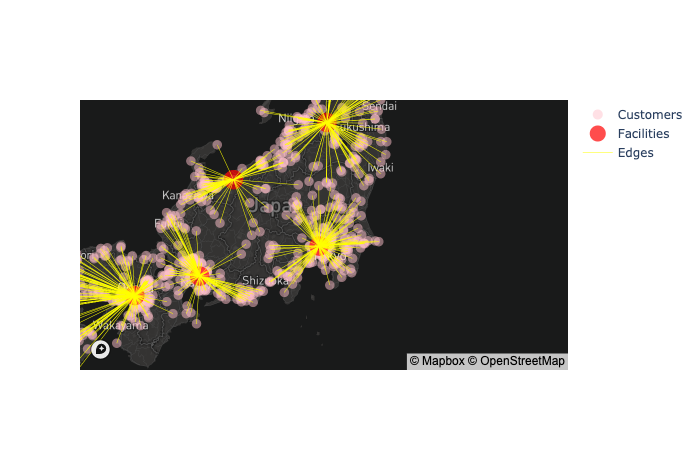
年間(計画期間)の総需要を計算する関数 make_total_demand
引数:
- demand_df: 需要データフレーム
- start: 計画期間の開始日
- finish: 計画期間の終了日
- num_of_days: 推定したい総需要の日数(既定値は365;すなわち年間需要量の推定)
返値:
- 総需要を入れたデータフレーム
make_total_demand
make_total_demand (demand_df, start='1900/01/01', finish='2050/12/31', num_of_days=365)
年間(計画期間)の総需要を計算する関数
demand_df = pd.read_csv(folder + "demand.csv")
total_demand_df, demand_cust_df, demand_prod_df = make_total_demand(demand_df, start="2019/01/01", finish="2050/12/31", num_of_days=365)
weight = demand_cust_df.demand.values
#total_demand_df = make_total_demand(demand_df)
total_demand_df.head()| prod | cust | demand | |
|---|---|---|---|
| 0 | A | さいたま市 | 3650.000000 |
| 1 | A | 京都市 | 28635.909091 |
| 2 | A | 仙台市 | 2123.636364 |
| 3 | A | 佐賀市 | 136908.181818 |
| 4 | A | 前橋市 | 5906.363636 |
顧客の集約
顧客の集約はロジスティクス・ネットワーク設計モジュールのrepeated_weiszfeldでできる.scikit-learnにも幾つのかのクラスタリング法が実装されているが,顧客の重み(需要量)を考慮したものとしてKmeans法とその変形があげられる.
これらの手法を用いて適切な顧客の集約を行うことを考える.
kmeans法を実行する関数 kmeans
kmeasn法は顧客の重み付き2乗距離の和を最小化する. 本来の重み付き距離の総和ではないが,高速なので大規模問題例に簡易的に使うことができる.
引数: - cust_df : 顧客データフレーム;緯度経度情報を利用する。 - weight : 顧客の重み;重み付きの大圏距離の和を最小化するものとする。 - num_of_facilities : 平面上に配置する施設の数を指定する。
返値: - X : 施設の緯度のリスト - Y : 施設の経度のリスト - partition : 顧客の割り当てられた施設の番号を格納したリスト - cost: 費用(重み付きの距離の総和)
kmeans
kmeans (cust_df, weight, num_of_facilities=1, batch=True)
kmeans関数の使用例
repeated_weiszfeldより悪いが,高速である.
X, Y, partition, cost = repeated_weiszfeld(cust_df, weight, num_of_facilities = 8, epsilon=0.0001, max_iter = 3, numpy=True, seed=1)
print(cost)490929454.9189146
CPU times: user 973 ms, sys: 1.3 ms, total: 974 ms
Wall time: 973 ms階層的クラスタリング関数 hierarchical_clusterning
hierarchical_clusterning
hierarchical_clusterning (cust_df, weight, durations, num_of_facilities=2, linkage='average')
階層的クラスタリング関数 hierarchical_clusterning
# durations, distances, node_df = compute_durations(cust_df, host=host)
# X, Y, partition, cost = hierarchical_clusterning(cust_df, weight, durations, num_of_facilities = 10, linkage="complete")
# print(cost)k-メディアン問題に対するLagrange緩和法
\(k\)-メディアン問題は,以下のように定義される問題であり,クラスタリングに有効である.
\(n\) 個の点(顧客とよぶ)から \(k (<n)\) 個の点(施設とよぶ)を選択することを考える. 選択された点を開設された施設と考え,各顧客は最も近い点に行ってサービスを受けるものとする. 顧客 \(i\) は需要量 \(w_i\) もち,地点 \(i,j\) 間の移動費用を \(c_{ij}\) とする. このとき,需要量と移動費用を乗じた量の合計を最小にするように,施設を開設する問題が \(k\)-メディアン問題である.
この問題は,以下のように数理最適化問題として定式化できる.
パラメータ: - \(n\): 点の数 - \(k\): 開設する施設の数 - \(c_{ij}\) : 地点 \(ij\) 間の1単位需要量あたりの移動費用 - \(w_{i}\) : 地点 \(i\) の需要量
変数:
- \(x_{ij}\) : 地点 \(i\) の顧客が施設 \(j\) でサービスを受けるとき \(1\), それ以外のとき \(0\) を表す\(0\)-\(1\)変数
- \(y_{j}\): 施設 \(j\) を開設するとき \(1\), それ以外のとき \(0\) を表す\(0\)-\(1\)変数
定式化:
\[ \begin{array}{lll} minimize & \sum_{ i,j } w_i c_{ij} x_{ij} & \\ s.t. & \sum_{j} x_{ij} = 1 & \forall i \\ & x_{ij} \leq y_j & \forall i,j \\ & \sum_{j} y_j = k & \end{array} \]
最初の制約式に対する Lagrange乗数を \(u_i\) とする. \(\bar{c}_{ij} = w_i c_{ij} - u_i\) と定義すると, Lagrange緩和問題は以下のようになる.
\[ \begin{array}{lll} L(u)= minimize & \sum_{ i,j } \bar{c}_{ij} x_{ij} +\sum_{i} u_i & \\ s.t. & x_{ij} \leq y_j & \forall i,j \\ & \sum_{j} y_j = k & \end{array} \]
任意のベクトル \(u\) に対して, \(L(u)\) は原問題の下界を与える. Lagrange緩和問題の最適解 \((x^*,y^*)\) は,以下の方法で求めることができる.
\(w_i \bar{c}_{ij} <0\) なら,顧客 \(i\) は施設 \(j\) に行くことを希望するだろう(だって,行くと儲かるから). 施設 \(j\) に来ることを希望する顧客から得られる総利益は, \(\sum_{i} [w_i \bar{c}_{ij}]^-\) と計算できる(ここで \([x]^-\) は \(\max (-x,0)\) を表す). この値の大きい順に \(k\) 個の施設を選択することによって,開設すべき施設を表すベクトル \(y^*\) を求めることができる. 開設している施設 \(j\) に対して \(w_i \bar{c}_{ij}\) が負になっている顧客 \(i\) はサービスを受けるので,\(x_{ij}^* =1\) とする.
施設 \(j\) が容量 \(M_j\) の上限をもつ容量制約付きの場合を考える. この場合のLagrange緩和問題は,施設 \(j\) ごとに以下の\(0\)-\(1\)ナップサック問題を解き,その最適値 \(z_j\) が正で大きいものから \(k\) 個の施設を選択すれば最適解を得ることができる.
\[ \begin{array}{llll} z_j = & maximize & \sum_{i} [\bar{c}_{ij}]^- x_{ij} & \\ & s.t. & \sum_{i} w_i x_{ij} \leq M_j & \forall j \end{array} \]
また,実務では制約における \(w_{ij}\) が \(1\) であることが多い.その際には,ナップサック問題の最適解は, \([w_i \bar{c}_{ij}]^-\) の大きい順に \(M_j\) 個選択することによって得ることができる.
さらには,各施設に割り当てられる顧客数は均等であることが望ましい.これは,1施設あたりの顧客数の平均値 \(n/k\) になるべく近くなるというペナルティを付加する.
\[ \sum_{j} \left(\sum_{i} x_{ij} - n/k \right)^2 \]
Lagrange緩和法では,下界を最大にする \(u\) を求める. \(u_i\) に対する劣勾配 \(g_i\) は, \(1- \sum_{j} x_{ij}^*\) であり,以下の反復法で最適化を行う.
\[ u_i := u_i + s \cdot g_i \ \ \ \forall i \]
ここで \(s\) はステップサイズを表すパラメータであり,以下のように決める.
最良の上界 \(ub\) とLanrange緩和による下界 \(lb\) と,劣勾配のノルム \(||g_i||\) を用いて,以下のパラメータ \(\alpha\) を導入する. \[ \alpha = (1.05 \cdot ub-lb)/norm \]
これにさらに反復 \(t\) ごとに変化するパラメータ \(\phi_t\) を乗じて,ステップサイズ \(s\) とする.
深層学習に対して有効性が確認されているfit-one-cycle法を応用する.
劣勾配法は不安定なので,慣性項 \(m_t\) (初期値は\(0\)ベクトル)を考慮するためのパラメータ \(\beta_t\) を導入し,以下のように移動平均をとることで,スムーズな勾配 \(m_t\) にする.
\[ m_t := \beta_t \cdot m_t + (1-\beta_t) \cdot g_t \]
反復 \(t\) におけるLagrange乗数ベクトル \(u\) の更新は, Adamを用いる.
\(\phi_t\) は, 最大学習率 max_lr と最小学習率 min_lr を用いて決める. 最大学習率は,予備的な実験である lr_finderを用いて決める. lr_finderでは,学習率(\(\phi_t\)に相当する)を非常に小さい値から始め, 反復ごとに2倍していく. 各反復に対する下界値をプロットしたときの,最大の山への入り口あたりが,最大学習率の推奨値となる. 最小学習率は,最大学習率の\(1/25\)倍あたりが推奨される.
慣性項のためのパラメータ\(\beta\) はその最小値と最大値を与える.通常は, \((0.85, 0.95)\) が良いとされている.
fit-one-cycle法では,学習率を制御するパラメータ \(\phi\) は徐々に大きくしていき,反復回数が半分に達したら,徐々に小さくしていく. 一方,慣性項のためのパラメータ\(\beta\)は徐々に小さくしていき,反復回数が半分に達したら,徐々に小さくしていく. ここでは,前半は最小値から最大値(最大値から最小値)まで直線的に変化させ,後半はcos関数を\(0\)から\(\pi\)まで変化させた曲線にしたがうようにパラメータを変化させる. ただし,学習率を制御するパラメータ \(\phi\) に対しては最小値を \(0\) とする.
以下に図示する.
k-メディアン問題の混合整数最適化による求解
需要量が1の輸送問題を解く関数 transporation
引数 - C: 費用行列 (\(n \times m\)) - capacity: 工場の容量(一定を仮定)
返値 - cost: 費用 - flow: フローを表す辞書
def transportation(C, capacity):
M = capacity
n,m = C.shape
C = np.ceil(C) # for network simplex
G =nx.DiGraph()
sum_ = 0
for j in range(m):
sum_ -= M
G.add_node(f"plant{j}", demand=-M)
for i in range(n):
sum_ += 1
G.add_node(i, demand= 1)
#add dummy customer with demand sum_
G.add_node("dummy", demand= -sum_)
for i in range(n):
for j in range(m):
G.add_edge(f"plant{j}", i, weight=C[i,j])
for j in range(m):
G.add_edge(f"plant{j}", "dummy", weight = 0)
cost, flow = nx.flow.network_simplex(G)
return cost, flowtransportationの使用例
c = {(1,1):4.5, (1,2):6, (1,3):9,
(2,1):5, (2,2):4, (2,3):7,
(3,1):6, (3,2):3, (3,3):4,
(4,1):8, (4,2):5, (4,3):3,
(5,1):10, (5,2):8, (5,3):4,
}
n = 5
m = 3
C = np.zeros( (n,m) )
for (i,j) in c:
C[i-1,j-1] = c[i,j]
cost, flow = transportation(C, capacity=3)クラスターの中心をもとめることによる上界の改善
def find_median(C, flow, n, m):
total_cost = 0
for j,f in enumerate(flow):
if j>=m:
break
cluster =[]
for i in range(n):
if flow[f][i]==1:
cluster.append(i)
if len(cluster)>1:
#find the best location for the cluster
nodes = np.array(cluster)
subC = C[np.ix_(nodes,nodes)]
best_location = nodes[subC.sum(axis=0).argmin()]
cost = subC.sum(axis=0).min()
total_cost+=cost
return total_cost# c = np.array(durations)
# C = c*weight.reshape((n,1))
# n = len(C)
# k = 10
# m = k
# M = int(len(cust_df)/k*1.2) #容量制約
# idx = np.array([0,1,2])
# idx = np.array([ 0,72,71,70,69,68,67,66,65,64])
# cost, flow = transportation(C[:,idx], capacity=M)
# find_median(C, flow, n, m)3794705.000033724k-メディアン問題を解くための関数 solve_k_median
引数: - cust_df : 顧客データフレーム;緯度経度情報を利用する。 - weight : 顧客の需要量 - cost: 移動費用(地図で求めたdurationsを入力する.) - num_of_facilities : 平面上に配置する施設の数を指定する。 - max_iter =100: 最大反復数 - max_lr =0.01: 最大学習率(ステップサイズ) - moms=(0.85,0.95): 慣性項の下限と上限 - convergence=1e-5: 収束判定のためのパラメータ - lr_find = False: 学習率探索を行う場合 True - adam = False: Adam法によるパラメータの調整を行う場合 True,上界と下界の差をもとに決める場合 False
返値: - X : 施設の緯度のリスト - Y : 施設の経度のリスト - partition : 顧客の割り当てられた施設の番号を格納したリスト - best_ub: 費み付きの費用の総和 - lb_list: 下界値の変化を入れたリスト - ub_list: 上界値の変化を入れたリスト - phi_list: 学習率探索の場合の学習率の変化を入れたリスト
solve_k_median
solve_k_median (cust_df, weight, cost, num_of_facilities, max_iter=100, max_lr=0.01, moms=(0.85, 0.95), convergence=1e-05, lr_find=False, adam=False, capacity=None)
k-メディアン問題を解くための関数 solve_k_median
solve_k_medianの使用例
# cust_df = generate_cust(num_locations = 100, random_seed = 3, prefecture = None , no_island=True)
# weight=np.random.random(len(cust_df))*10
# durations, distances, node_df = compute_durations(cust_df, host=host)# %%time
# X, Y, partition, best_ub, lb_list, ub_list, phi_list = solve_k_median(cust_df, weight, durations, num_of_facilities=10,
# max_iter=10000, max_lr=20., moms=(0.85,0.95), convergence=1e-5, lr_find = False, adam=True, capacity = None)k-メディアンの学習率探索の結果を可視化する関数 plot_k_median_lr_find
引数: - phi_list: 学習率設定のパラメータ \(\Phi\) の変化を入れたリスト - lb_list: 下界の変化を入れたリスト
返値: - Plotlyの図オブジェクト
plot_k_median_lr_find
plot_k_median_lr_find (phi_list, lb_list)
k-メディアンの学習率探索の結果を可視化する関数 plot_k_median_lr_find
plot_k_median_lr_find関数の使用例
# fig = plot_k_median_lr_find(phi_list, lb_list)
# plotly.offline.plot(fig);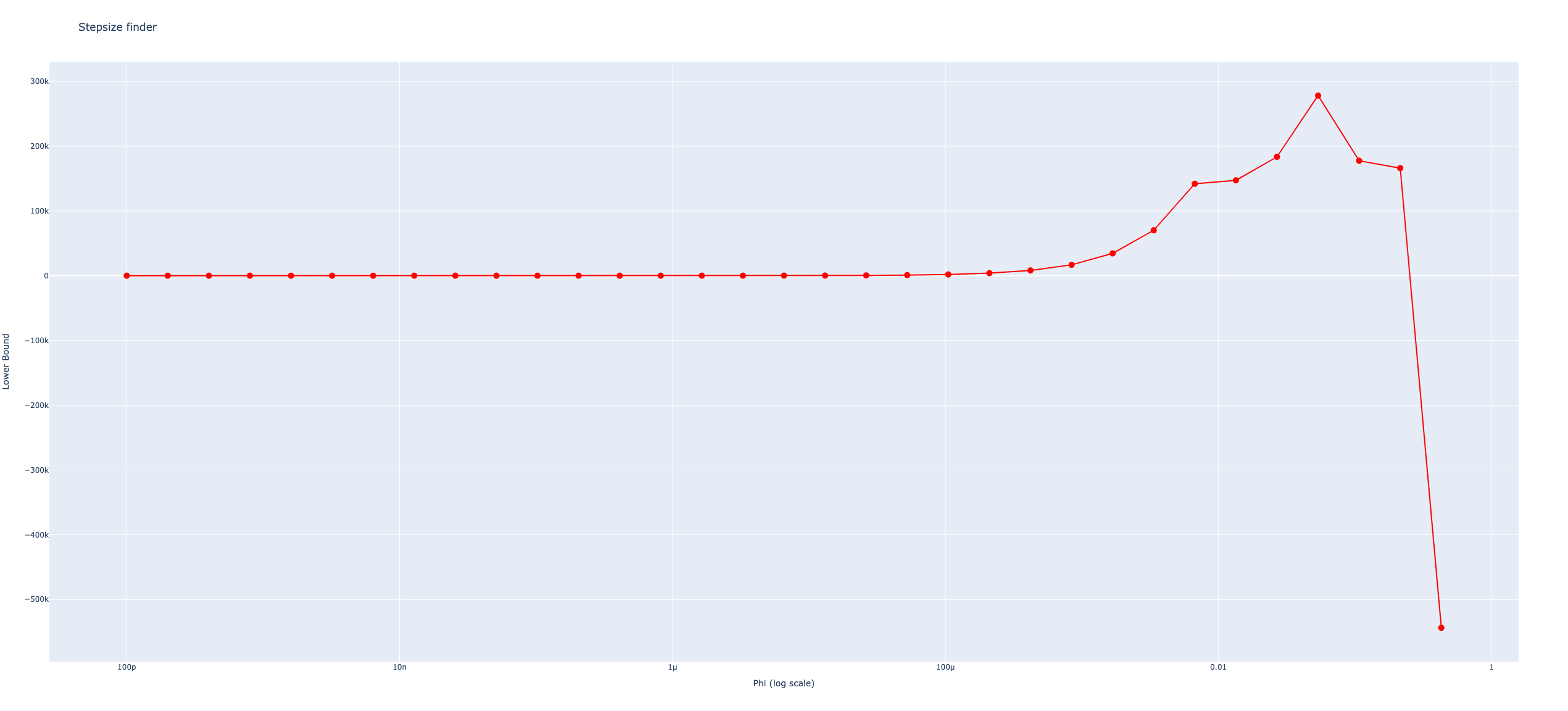
k-メディアン最適化の探索を可視化する関数 plot_k_median
引数: - lb_list: 下界の変化を入れたリスト - ub_list: 上界の変化を入れたリスト
返値: - fig: 下界と上界の変化を可視化した図オブジェクト
plot_k_median
plot_k_median (lb_list, ub_list)
plot_k_median関数の使用例
# fig = plot_k_median(lb_list, ub_list)
# plotly.offline.plot(fig);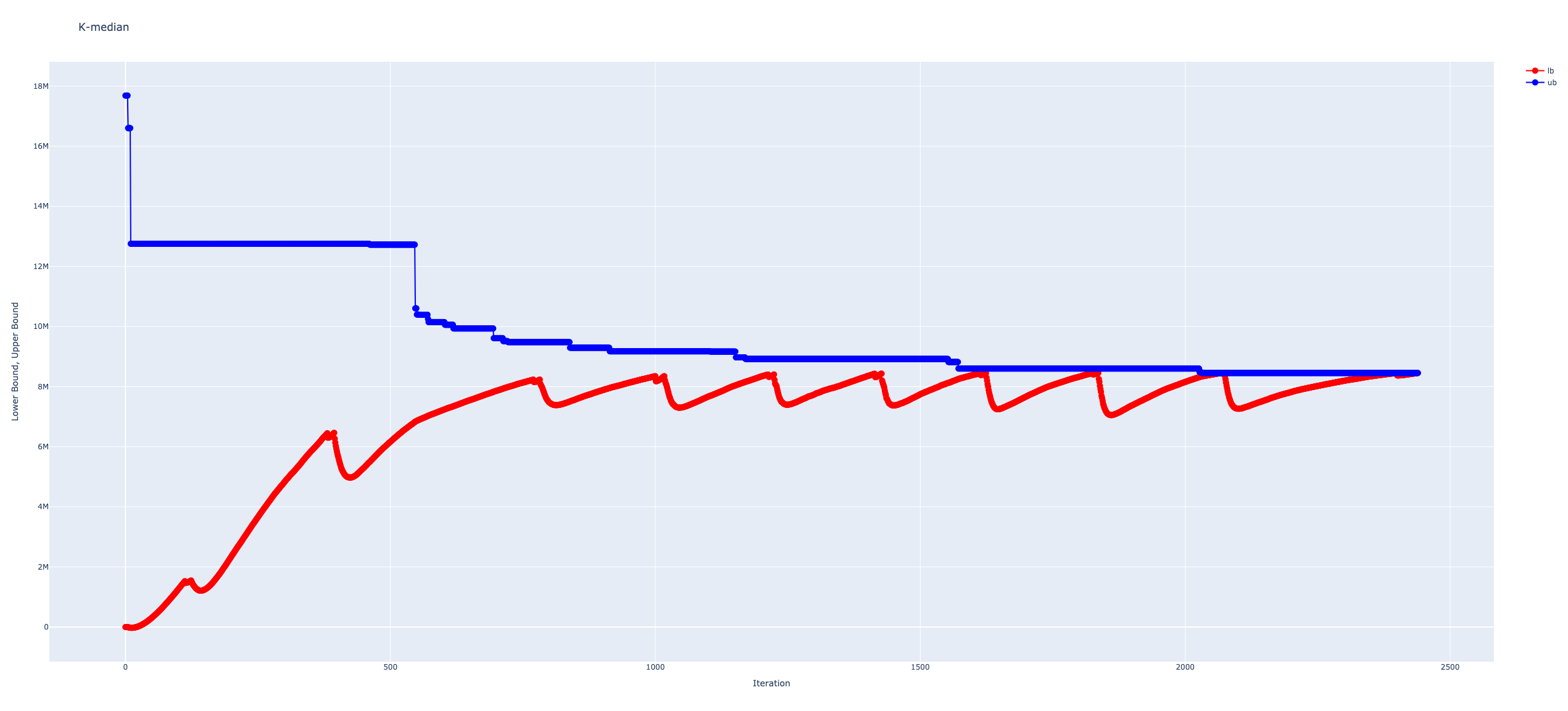
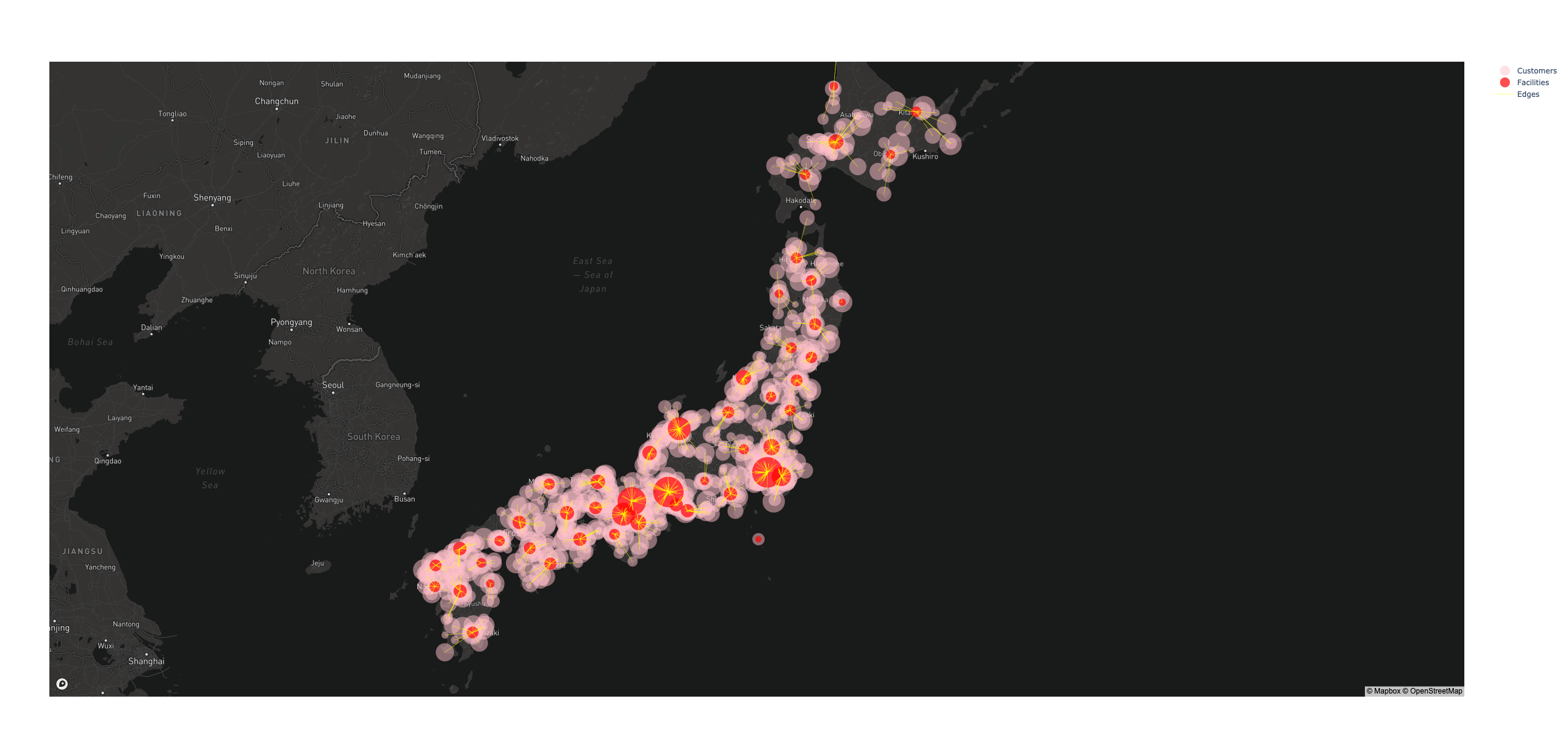
k-メディアン法で得られた結果
エルボー法を実行する関数 elbow_method
施設数を変化させたときの費用の変化を描画する関数. 費用があまり変化しなくなった点が適切な施設数であると考えられる. その点が肘を曲げたときの格好に似ていることから,エルボー法と呼ばれるヒューリスティクスである.
引数: - cust_df : 顧客データフレーム;緯度経度情報を利用する。 - weight : 顧客の重み;重み付きの大圏距離の和を最小化するものとする。 - n_lb: 施設数の下限値 - n_ub: 施設数の上限値 - repetitions: 同一の施設数での実験回数 - method: 施設を求める手法を表す文字列. “kmeans”のときkmeans法,“weiszfeld”のとき反復Weiszfeld法,“hierarchical”のとき階層的クラスタリング法を用いる. - durations: 階層的クラスタリング法を用いるときの地点間の移動時間行列
返値: - 施設数を変化させたときの費用の変化を示したPlotlyの図オブジェクト
elbow_method
elbow_method (cust_df, weight, n_lb=1, n_ub=10, repetitions=3, method='kmeans', durations=None)
elbow method
elbow_method関数の使用例
# fig = elbow_method(cust_df, weight, n_lb = 10, n_ub = 30, repetitions=1, method="hierarchical", durations=durations)#階層クラスタリングは繰り返しても同じ結果
# #plotly.offline.plot(fig);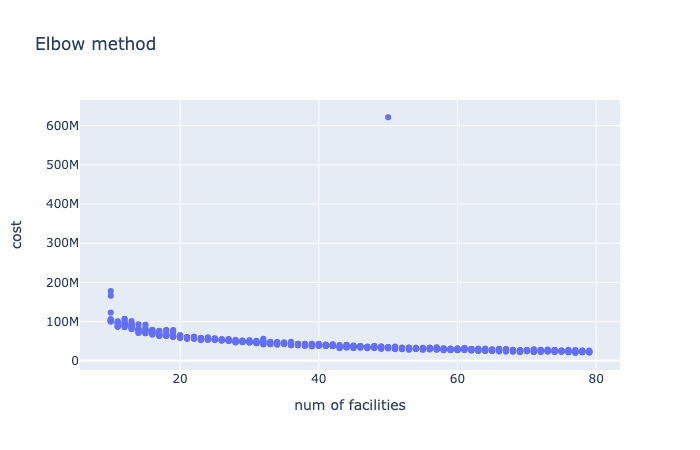
施設数(集約数)は50程度が良さそうなので,集約した顧客を生成
集約した顧客のデータを生成する関数 make_aggregated_customer_df
引数: - cust_df : 顧客データフレーム;緯度経度情報を利用する。 - X : 施設の緯度のリスト - Y : 施設の経度のリスト - partition : 顧客の割り当てられた施設の番号を格納したリスト - weight: 顧客の需要量合計
返値: - aggregated_cust_df: 集約した顧客データフレーム
make_aggregated_cust_df
make_aggregated_cust_df (cust_df, X, Y, partition, weight)
make aggregated customer dataframe
aggregated_cust_df = make_aggregated_cust_df(cust_df, X, Y, partition, weight)
aggregated_cust_df.head()| name | lat | lon | customers | demand | |
|---|---|---|---|---|---|
| 0 | cust0 | 35.170125 | 136.885273 | [0, 1, 7, 8, 9, 14, 17, 19, 20, 25, 27, 32, 33... | 2.442427e+06 |
| 1 | cust1 | 33.645909 | 130.691511 | [30, 47, 80, 93, 104, 106, 111, 122, 130, 131,... | 5.168430e+05 |
| 2 | cust2 | 34.627574 | 133.877177 | [5, 12, 38, 50, 61, 73, 74, 82, 89, 94, 95, 11... | 7.142208e+05 |
| 3 | cust3 | 32.036018 | 130.764068 | [10, 13, 107, 206, 219, 275, 308, 482, 519, 52... | 3.964662e+04 |
| 4 | cust4 | 38.208808 | 140.282584 | [2, 15, 16, 21, 29, 31, 34, 44, 46, 59, 60, 66... | 5.405169e+05 |
集約した顧客のデータと需要データを生成する関数 make_aggregated_df
引数: - cust_df : 顧客データフレーム;緯度経度情報を利用する。 - demand_df: 需要データフレーム(現在は使用していないので,なくても良い) - total_demand_df: 年間総需要のデータフレーム - X : 施設の緯度のリスト - Y : 施設の経度のリスト - partition : 顧客の割り当てられた施設の番号を格納したリスト - weight: 顧客の需要量合計
返値: - aggregated_cust_df: 集約した顧客データフレーム - aggregated_demand_df: 集約した需要データフレーム (遅いので省いた.) - aggregated_total_demand_df: 集約した総需要データフレーム
make_aggregated_df
make_aggregated_df (cust_df, demand_df, total_demand_df, X, Y, partition, weight)
make aggregated dataframe
make_aggregated_df関数の使用例
aggregated_cust_df, aggregated_total_demand_df = make_aggregated_df(cust_df, demand_df, total_demand_df, X, Y, partition, weight)
#aggregated_cust_df.to_csv(folder+"agg_cust.csv")
aggregated_total_demand_df.head()| prod | cust | demand | |
|---|---|---|---|
| 0 | A | cust0 | 79615.123626 |
| 1 | A | cust1 | 15948.695055 |
| 2 | A | cust2 | 27322.857143 |
| 3 | A | cust3 | 9509.052198 |
| 4 | A | cust4 | 30050.329670 |
集約データに対する倉庫データ生成
複数ソースモデルの定式化
集合・パラメータ・変数を以下に示す.
集合:
- \(Cust\) : 顧客(群)の集合
- \(Dc\) : 倉庫の集合
- \(Plnt\) : 工場の集合
- \(Prod\) : 製品(群)の集合
パラメータ:
需要量,固定費用,取扱量(生産量)上下限の数値は,単位期間(既定値は365日)に変換してあるものとする.
- \(c_{ij}\) : 地点 \(ij\) 間の1単位重量あたりの移動費用
- \(w_{p}\) : 製品 \(p\) の重量
- \(vol_{p}\): 製品 \(p\) の容量を表す辞書;既定値はNoneでその場合には容量は1に設定される.
- \(d_{kp}\) : 顧客 \(k\) における製品 \(p\) の需要量
- \(LB_j, UB_j\) : 倉庫 \(j\) の取扱量の下限と上限;入庫する製品量の下限と上限を表す.
- \(NLB, NUB\) : 開設する倉庫数の下限と上限
- \(f_j\) : 倉庫 \(j\) を開設する際の固定費用
- \(v_j\) : 倉庫 \(j\) における製品1単位あたりの変動費用
- \(PLB_{ip}, PUB_{ip}\) : 工場 \(i\) における製品 \(p\) の生産量上限
変数:
\(x_{ijp}\) : 地点 \(ij\) 間の製品 \(p\) のフロー量
\(y_{j}\): 倉庫 \(j\) を開設するとき \(1\), それ以外のとき \(0\) を表す\(0\)-\(1\)変数
定式化:
\[ \begin{array}{lll} minimize & \sum_{ i \in Plnt, j \in Dc, p \in Prod} (w_p c_{ij} + v_j) x_{ijp} + \sum_{j \in Dc, k \in Cust, p \in Prod} w_p c_{jk} x_{jkp} + \sum_{j \in Dc} f_j y_j & \\ s.t. & \sum_{j \in Dc} x_{jkp} = d_{kp} & \forall k \in Cust, p \in Prod \\ & \sum_{ i \in Plnt} x_{ijp} = \sum_{k \in Cust} x_{jkp} & \forall j \in Dc, p \in Prod \\ & x_{jkp} \leq d_{kp} y_j & \forall j \in Dc, k \in Cust, p \in Prod \\ & LB_j y_j \leq \sum_{i \in Plnt, p \in Prod} vol_{p} x_{ijp} \leq UB_j y_j & \forall j \in Dc \\ & \sum_{j \in Dc} x_{ijp} \leq PUB_{ip} & \forall i \in Plnt, p \in Prod \\ & NUB \leq \sum_{j in Dc} y_j \leq NUB & \end{array} \]
lnd_ms
lnd_ms (weight, cust, dc, dc_lb, dc_ub, plnt, plnt_ub, demand, tp_cost, del_cost, dc_fc, dc_vc, dc_num, volume=None, fix_y=None, dc_slack_penalty=10000.0, demand_slack_penalty=10000000.0)
単一ソースモデルの定式化
集合・パラメータ・変数を以下に示す.
集合:
- \(Cust\) : 顧客(群)の集合
- \(Dc\) : 倉庫の集合
- \(Plnt\) : 工場の集合
- \(Prod\) : 製品(群)の集合
パラメータ:
需要量,固定費用,取扱量(生産量)上下限の数値は,単位期間(既定値は365日)に変換してあるものとする.
- \(c_{ij}\) : 地点 \(ij\) 間の1単位重量あたりの移動費用
- \(w_{p}\) : 製品 \(p\) の重量
- \(vol_{p}\): 製品 \(p\) の容量を表す辞書;既定値はNoneでその場合には容量は1に設定される.
- \(d_{kp}\) : 顧客 \(k\) における製品 \(p\) の需要量
- \(LB_j, UB_j\) : 倉庫 \(j\) の取扱量の下限と上限;入庫する製品量の下限と上限を表す.
- \(NLB, NUB\) : 開設する倉庫数の下限と上限
- \(f_j\) : 倉庫 \(j\) を開設する際の固定費用
- \(v_j\) : 倉庫 \(j\) における製品1単位あたりの変動費用
- \(PLB_{ip}, PUB_{ip}\) : 工場 \(i\) における製品 \(p\) の生産量上限
変数:
\(x_{ijp}\) : 地点 \(ij\) 間の製品 \(p\) のフロー量
\(y_{j}\): 倉庫 \(j\) を開設するとき \(1\), それ以外のとき \(0\) を表す\(0\)-\(1\)変数
\(z_{jk}\): 顧客 \(k\) が倉庫 \(j\) から配送されるとき \(1\), それ以外のとき \(0\) を表す\(0\)-\(1\)変数
定式化:
\[ \begin{array}{lll} minimize & \sum_{ i \in Plnt, j \in Dc, p \in Prod} (w_p c_{ij} + v_j) x_{ijp} + \sum_{j \in Dc, k \in Cust, p \in Prod} w_p c_{jk} d_{kp} z_{jk} + \sum_{j \in Dc} f_j y_j & \\ s.t. & \sum_{j \in Dc} z_{jk} = 1 & \forall k \in Cust \\ & \sum_{ i \in Plnt} x_{ijp} = \sum_{k \in Cust} d_{kp} z_{jk} & \forall j \in Dc, p \in Prod \\ & z_{jk} \leq y_j & \forall j \in Dc, k \in Cust \\ & LB_j y_j \leq \sum_{i \in Plnt, p \in Prod} vol_{p} x_{ijp} \leq UB_j y_j & \forall j \in Dc \\ & \sum_{j \in Dc} x_{ijp} \leq PUB_{ip} & \forall i \in Plnt, p \in Prod \\ & NUB \leq \sum_{j in Dc} y_j \leq NUB & \end{array} \]
lnd_ss
lnd_ss (weight, cust, dc, dc_lb, dc_ub, plnt, plnt_ub, demand, tp_cost, del_cost, dc_fc, dc_vc, dc_num, volume=None, fix_y=None, dc_slack_penalty=10000.0, demand_slack_penalty=10000000.0)
地点間の距離の分布の可視化関数 distance_histgram
実際問題においては、あまり遠い倉庫から顧客に配送することは少なく、同じように、工場から倉庫への輸送もあまり遠いものは行わない。 そのため、遠い距離の輸送・配送経路は、あらかじめ削除しておいた方が効率的だ。 ただし、特定の工場でしか生産されたいないものは、その工場から運ぶしかないので、経路を削除しすぎると実行不能になってしまう。
以下では、そのための指針になるような可視化を考える。まずは、距離のヒストグラムを表示する。
distance_histgram
distance_histgram (cust_df, dc_df, plnt_df, distances=None)
工場・倉庫間と倉庫・顧客間の距離のヒストグラムを返す関数
distance_histgram関数の使用例
# cust_df = pd.read_csv(folder+"cust.csv", index_col="id")
# dc_df = pd.read_csv(folder+"DC.csv", index_col=0)
# plnt_df = pd.read_csv(folder+"Plnt.csv", index_col=0)
# fig = distance_histgram(cust_df, dc_df, plnt_df, distances=distances)
# plotly.offline.plot(fig);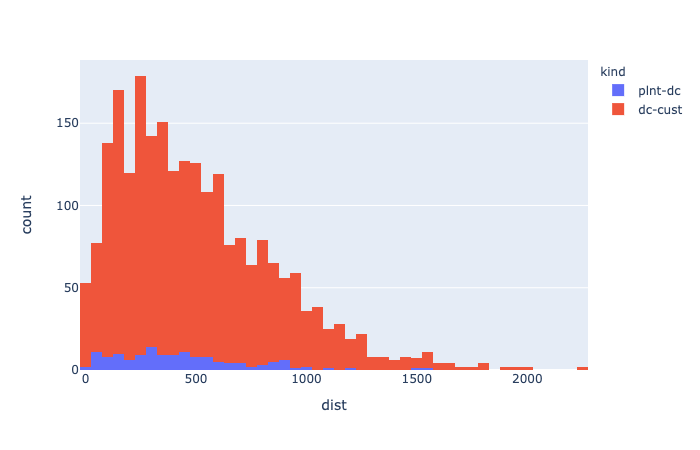
輸送・配送経路の生成関数 make_network_using_road
輸送経路(工場と倉庫間)と配送経路(倉庫と顧客間)を生成する関数(道路距離と移動時間で計算する場合)
引数: - cust_df : 顧客データフレーム - dc_df : 倉庫データフレーム - plnt_df : 工場データフレーム - durations: 移動時間を入れた配列(最初は顧客=倉庫,その後に工場);単位は秒 (パスがない場合に大圏距離から算出;時速50kmと仮定) - distances: 移動距離を入れた配列(最初は顧客=倉庫,その後に工場);単位はm (パスがない場合には大圏距離の10倍と設定) - plnt_dc_threshold : 工場・倉庫間の距離の上限 (km) - dc_cust_threshold : 倉庫・顧客間の距離の上限 (km) - tc_per_dis : 工場・倉庫間の単位距離・重量あたりの輸送費用 (円/km/単位重量) - dc_per_dis : 倉庫・顧客間の単位距離・重量あたりの輸送費用 (円/km/単位重量) - tc_per_time : 工場・倉庫間の単位時間・重量あたりの輸送費用 (円/h/単位重量) - dc_per_time : 倉庫・顧客間の単位時間・重量あたりの輸送費用 (円/h/単位重量) - lt_lb : リード時間(単位は日で自然数)を決めるためのパラメータで、最短リード時間(発注から到着までの最短日数)を与える。 - lt_threshold: リード時間(単位は日で自然数)を決めるためのパラメータ;移動距離がこの値を超えたときには、1日を加算する。 - stage_time_bound: 点上での処理に必要な時間(生産時間、処理時間)を生成のための下限と上限のタプル
返値: - trans_df : 輸配送ネットワークのデータフレーム;列は以下の通り。 - from_node : 出発地点 - to_node : 到着地点
- dist : 距離 (km) - time : 移動時間 (h) - cost : 費用 (円) - lead_time : リード時間 - stage_time: 点上での処理に必要な時間(生産時間、処理時間) - kind: 経路の種類 (“plnt-dc”, “dc-cust”のいずれかの文字列) - graph : networkXのグラフインスタンス - position : networkXの点の位置(経度、緯度のタプル)
点を表す辞書のキーに対しては、同名の工場,倉庫,顧客がある場合にエラーするので, 工場は “Plnt_”、倉庫は “DC_”、顧客は “Cust_”を先頭に負荷して区別するものとする。
make_network_using_road
make_network_using_road (cust_df, dc_df, plnt_df, durations, distances, plnt_dc_threshold=999999.0, dc_cust_threshold=999999.0, tc_per_dis=0.001, dc_per_dis=0.0025, tc_per_time=0.4, dc_per_time=2.0, lt_lb=1, lt_threshold=800.0, stage_time_bound=(1, 1))
輸送・配送経路の生成
# cust_df = pd.read_csv(folder + "cust.csv")
# dc_df = pd.read_csv(folder + "DC.csv")
# plnt_df = pd.read_csv(folder + "Plnt.csv")
# durations, distances, node_df = compute_durations(cust_df, plnt_df, host=host)
# trans_df, graph, position = make_network_using_road(cust_df, dc_df, plnt_df, durations, distances, plnt_dc_threshold = 10000., dc_cust_threshold = 200. )
# #trans_df.to_csv(folder + "trans_cost.csv")
# trans_df.head()生成したネットワークの簡易可視化
Plotlyでの描画は,後で述べるplot_scmを使う.
# %matplotlib inline
# nx.draw(graph,pos=position)
輸送・配送経路の生成関数 make_network
輸送経路(工場と倉庫間)と配送経路(倉庫と顧客間)を生成する関数(大圏距離で近似する場合)
引数: - cust_df : 顧客データフレーム - dc_df : 倉庫データフレーム - plnt_df : 工場データフレーム - plnt_dc_threshold : 工場・倉庫間の距離の上限 (km) - dc_cust_threshold : 倉庫・顧客間の距離の上限 (km) - unit_tp_cost : 工場・倉庫間の単位距離・重量あたりの輸送費用 (円/km/単位重量) - unit_del_cost : 倉庫・顧客間の単位距離・重量あたりの配送費用 (円/km/単位重量) - lt_lb : リード時間(単位は日で自然数)を決めるためのパラメータで、最短リード時間(発注から到着までの最短日数)を与える。 - lt_threshold: リード時間(単位は日で自然数)を決めるためのパラメータ;移動距離がこの値を超えたときには、1日を加算する。 - stage_time_bound: 点上での処理に必要な時間(生産時間、処理時間)を生成のための下限と上限のタプル
返値: - trans_df : 輸配送ネットワークのデータフレーム;列は以下の通り。 - from_node : 出発地点 - to_node : 到着地点
- dist : 距離 (km) - cost : 費用 (円) - lead_time : リード時間 - stage_time: 点上での処理に必要な時間(生産時間、処理時間) - kind: 経路の種類 (“plnt-dc”, “dc-cust”のいずれかの文字列) - graph : networkXのグラフインスタンス - position : networkXの点の位置(経度、緯度のタプル)
点を表す辞書のキーに対しては、同名の工場,倉庫,顧客がある場合にエラーするので, 工場は “Plnt_”、倉庫は “DC_”、顧客は “Cust_”を先頭に負荷して区別するものとする。
make_network
make_network (cust_df, dc_df, plnt_df, plnt_dc_threshold=999999.0, dc_cust_threshold=999999.0, unit_tp_cost=1.0, unit_del_cost=1.0, lt_lb=1, lt_threshold=800.0, stage_time_bound=(1, 1))
輸送・配送経路の生成:
make_network関数の使用例
# cust_df = pd.read_csv(folder + "cust.csv")
# dc_df = pd.read_csv(folder + "DC.csv")
# plnt_df = pd.read_csv(folder + "Plnt.csv")
# prod_df = pd.read_csv(folder + "Prod.csv")
# plnt_prod_df = pd.read_csv(folder + "Plnt-Prod.csv")
# trans_df, graph, position = make_network(cust_df, dc_df, plnt_df, plnt_dc_threshold = 10000.,
# dc_cust_threshold = 200.,unit_tp_cost = 1., unit_del_cost = 10., lt_lb =3, lt_threshold = 800.,stage_time_bound=(1,2))
# #trans_df.to_csv(folder + "trans_cost.csv")
# trans_df.head()| from_node | to_node | dist | cost | lead_time | stage_time | kind | |
|---|---|---|---|---|---|---|---|
| 0 | Odawara | 札幌市 | 884.563252 | 884.563252 | 5 | 2 | plnt-dc |
| 1 | Odawara | 青森市 | 630.586550 | 630.586550 | 4 | 2 | plnt-dc |
| 2 | Odawara | 盛岡市 | 520.723595 | 520.723595 | 4 | 1 | plnt-dc |
| 3 | Odawara | 仙台市 | 363.801278 | 363.801278 | 4 | 2 | plnt-dc |
| 4 | Odawara | 秋田市 | 499.430315 | 499.430315 | 4 | 2 | plnt-dc |
需要が0の地点を除く関数 remove_zero_cust
実際問題では、年間需要が全くない顧客がいる可能性がある。これは、データベースに登録された顧客だが、1年間全く発注しなかったものや、 統廃合によってすでにない顧客などがあげられる。これをあらかじデータからのぞいておく関数が、以下のremove_zero_custである。
引数: - cust_df: 顧客データフレーム - demand_df: 需要データフレーム
返値: - 新しい(需要が0の顧客を除いた)顧客データフレーム(需要量の合計を表す列が追加されている)。
倉庫の配置候補地点を顧客上としている場合には、倉庫の候補地点からも除くべきであるが、必ずしも除く必要がない場合もあるので、除く必要がある場合には、手作業で削除するものとする。
remove_zero_cust
remove_zero_cust (cust_df, demand_df)
需要が0の地点を除く関数
# demand_df = pd.read_csv(folder+"demand.csv")
# new_cust_df = remove_zero_cust(cust_df, demand_df)
# new_cust_df.head()| id | name | lat | lon | total_demand | |
|---|---|---|---|---|---|
| 0 | 1 | 札幌市 | 43.06417 | 141.34694 | 0.229589 |
| 1 | 2 | 青森市 | 40.82444 | 140.74000 | 0.331507 |
| 2 | 3 | 盛岡市 | 39.70361 | 141.15250 | 0.166849 |
| 3 | 4 | 仙台市 | 38.26889 | 140.87194 | 0.198630 |
| 4 | 5 | 秋田市 | 39.71861 | 140.10250 | 0.210959 |
総需要が0の顧客を除く関数 remove_zero_total_demand
remove_zero_total_demand
remove_zero_total_demand (total_demand_df, cust_df)
remove_zero_total_demand関数の使用例
# total_demand_df = pd.read_csv("Cust-Prod.csv")
# total_demand_df.columns=["cust","prod","demand"]
# cust_df = pd.read_csv("cust.csv")
# cust_df.columns= ["name","lat","lon"]
# cust_df["lat"] = cust_df["lat"].astype(float)
# cust_df["lon"] = cust_df["lon"].astype(float)
# new_cust_df = remove_zero_total_demand(total_demand_df, cust_df)
# new_cust_df| name | lat | lon | |
|---|---|---|---|
| 0 | 191 | 43.055874 | 141.367475 |
| 1 | 221 | 43.036309 | 141.439051 |
| 2 | 396 | 41.826084 | 140.725339 |
| 3 | 560 | 36.031805 | 139.630817 |
| 4 | 590 | 43.797487 | 142.403188 |
| ... | ... | ... | ... |
| 758 | 9905855 | 34.471059 | 132.387806 |
| 759 | 9908978 | 33.687982 | 130.486641 |
| 760 | 9909893 | 35.672854 | 139.817410 |
| 761 | 9921389 | 35.325564 | 136.917991 |
| 762 | 9926062 | 34.705796 | 135.345729 |
763 rows × 3 columns
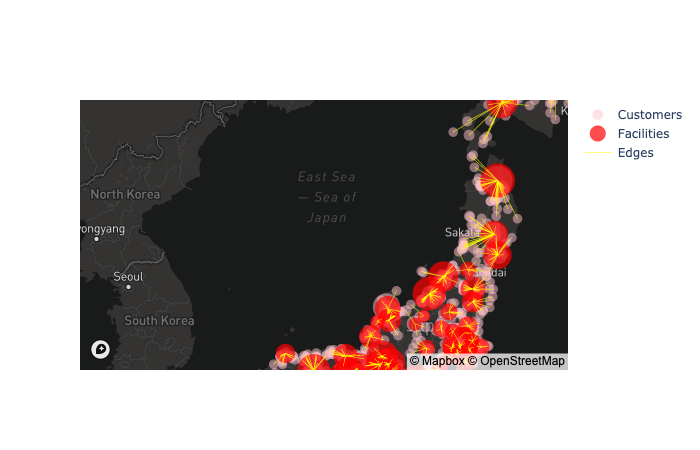
サプライ・チェイン全体の可視化関数 plot_scm
引数: - cust_df : 顧客データフレーム - dc_df : 倉庫データフレーム - plnt_df : 工場データフレーム - graph : NetworkXのグラフインスタンス - position : NetworkXの点の位置(経度、緯度のタプル) - node_only: 点だけを表示するとき True
返値: - PlotlyのFigureオブジェクト(顧客、倉庫、工場と輸配送経路)
plot_scm
plot_scm (cust_df, dc_df, plnt_df, graph, position, node_only=False)
顧客、倉庫、工場データフレームを入れると、PlotlyのFigureオブジェクトに地図を入れて返す関数
plot_scm関数の使用例
#cust_df = pd.read_csv("cust.csv")
#dc_df = pd.read_csv("DC.csv")
#plnt_df = pd.read_csv("Plnt.csv")
# fig = plot_scm(cust_df, dc_df, plnt_df, graph, position)
# plotly.offline.plot(fig);
数値の桁数を表示する関数 digit_histgram
需要データと輸配送費用の数値の桁数(ならびに小数点以下の桁数)をヒストグラムで表示する。
digit_histgram
digit_histgram (df, col_name='')
数値の桁数のヒストグラムを返す関数
digit_histgram関数の使用例
年間需要データフレームの需要列の桁数
輸配送データフレームの費用列の桁数
#fig = digit_histgram(total_demand_df, "demand")
#plotly.offline.plot(fig);
# fig = digit_histgram(trans_df, "cost")
# plotly.offline.plot(fig);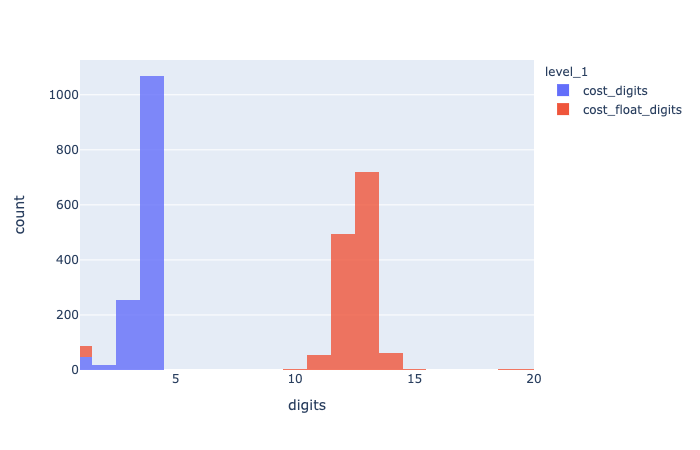
桁数を丸め
小数以下の桁数を丸めることによって、最適化が高速になる。以下では、需要を小数点2以下2桁で丸め、輸配送費用を整数に丸めている。
# rounded_total_demand_df = total_demand_df.round({"demand":2})
# rounded_trans_df = trans_df.round({"cost":0})#rounded_total_demand_df.head()| prod | cust | demand | |
|---|---|---|---|
| 0 | A | さいたま市 | 85.23 |
| 1 | A | 京都市 | 67.18 |
| 2 | A | 仙台市 | 75.21 |
| 3 | A | 佐賀市 | 84.23 |
| 4 | A | 前橋市 | 67.18 |
年間需要量 total_demand.csv ならびに輸送費用 trans_cost.csv として保管
データフレームからロジスティクス・ネットワーク設計モデルを解く関数
引数: - prod_df: 製品データフレーム - cust_df : 顧客データフレーム - dc_df : 倉庫データフレーム(固定費用、変動費用を追加) - plnt_df : 工場データフレーム - plnt_prod_df: 工場・製品データフレーム - total_demand_df: 総需要データフレーム - trans_df: 輸送ネットワークデータフレーム - dc_num: 開設したい倉庫数;下限と上限を指定したい場合にはタプル. 既定値は None で指定なし. - single_sourcing: 単一ソースの場合にTrue、それ以外のときFalse - max_cpu: 計算時間上限
返値:
- flow_df: 輸・配送量が正の経路を入れたデータフレーム
- dc_df: 倉庫の開設の有無を表す列 (open_close) を追加
- cost_df: 費用の内訳を入れたデータフレーム
- violation_df: 制約の逸脱量を入れたデータフレーム
- Status: 最適化の状態(2でない場合は最適でない)
solve_lnd
solve_lnd (prod_df, cust_df, dc_df, plnt_df, plnt_prod_df, total_demand_df, trans_df, dc_num=None, single_sourcing=True, max_cpu=100)
データフレームからロジスティック・ネットワーク設計モデルを解く関数
solve_lnd関数の使用例
# cust_df = pd.read_csv(folder + "cust.csv")
# plnt_df = pd.read_csv(folder + "Plnt.csv")
# total_demand_df = pd.read_csv(folder + "demand.csv")
# trans_df = pd.read_csv(folder + "trans_cost.csv")
# dc_df = pd.read_csv(folder + "DC.csv")
# prod_df = pd.read_csv(folder + "Prod.csv")
# plnt_prod_df = pd.read_csv(folder + "Plnt-Prod.csv")
# try:
# flow_df, dc_df, cost_df, violation_df, status = solve_lnd(prod_df, cust_df, dc_df, plnt_df, plnt_prod_df, total_demand_df,
# trans_df, dc_num= (5,10), single_sourcing=True, max_cpu = 10)
# except SolverError as e:
# print(e)
# if status != 2:
# if status == 3:
# print("Infeasible solution")
# elif status == 4:
# print( "Infeasible or unbounded")
# elif status == 5:
# print("Unbounded solution")
# else:
# print("Failed to find an optimal solution")
# else:
# print(cost_df) cost value
0 total cost 5.096749e+07
1 transportation (plant to dc) 2.836256e+07
2 delivery (dc to customer) 2.249198e+07
3 dc fixed 1.055960e+05
4 dc variable 7.356548e+03
5 infeasible penalty 0.000000e+00#費用の可視化
# fig = px.bar(cost_df, y="cost", x="value", orientation='h')
# plotly.offline.plot(fig);結果の可視化関数 show_optimized_network
引数: - cust_df: 顧客データフレーム - dc_df: 倉庫データフレーム - plnt_df: 工場データフレーム - prod_df: 製品データフレーム - flow_df: 最適化されたフロー量を保管したデータフレーム - position : NetworkXの点の位置(経度、緯度のタプル)
返値: - Plotlyの図オブジェクト
show_optimized_network
show_optimized_network (cust_df, dc_df, plnt_df, prod_df, flow_df, position)
顧客、倉庫、工場、輸・配送データフレームを入れると、PlotlyのFigureオブジェクトに地図を描画
show_optimized_network関数の使用例
#fig = show_optimized_network(cust_df, dc_df, plnt_df, prod_df, flow_df, position)
#plotly.offline.plot(fig);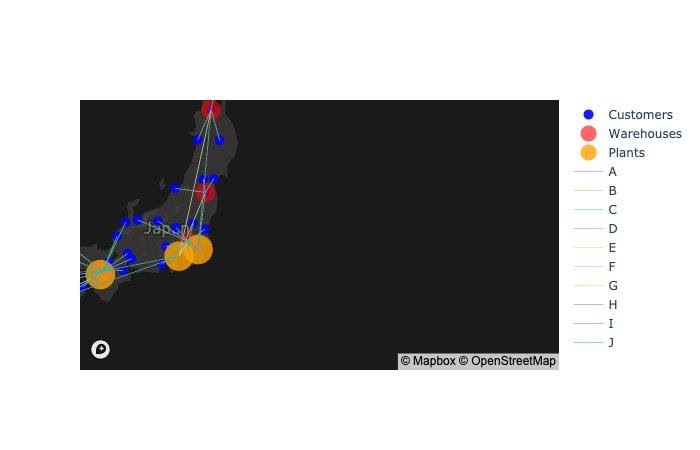
Excelインターフェィス
Excelのテンプレートを生成する関数 make_excel_melos
返値: - wb: ExcelのWorkBook;以下のシートと列をもつ.
倉庫候補地点
- lb: 容量下限
- ub: 容量上限
- fc: 固定費用
- vc: 変動費用
製品
- name: 製品の名称
- weight: 製品の重量 (単位はkg)
- volume: 製品の容量 (単位は 𝑚3 )
make_excel_melos
make_excel_melos ()
wb = make_excel_melos()
wb.save("melos-templete.xlsx")需要(顧客・製品)と生産(工場・製品)シートの生成関数 make_demand_production_sheets
基本テンプレートにデータを入力後に,需要(顧客・製品)と生産(工場・製品)シートを追加する.
引数: - wb: 基本テンプレートのExcel Workbook
返値: - wb: 需要シートと生産シートを追加した Excel Workbook
make_demand_production_sheets
make_demand_production_sheets (wb)
# wb = load_workbook("melos-templete.xlsx", data_only=True)
# wb = make_demand_production_sheets(wb)
# wb.save("melos-ex2.xlsx")Excel Workbookからデータフレームを生成する関数 prepare_df_for_melos
データを入力したExcel Workbookからデータフレームを生成する.
引数: - wb: データ入力済みExcel Workbook
返値: - cust_df : 顧客データフレーム - dc_df : 倉庫データフレーム - plnt_df : 工場データフレーム - prod_df: 製品データフレーム - demand_df: 需要データフレーム - production_df: 生産データフレーム
prepare_df_for_melos
prepare_df_for_melos (wb)
# wb = load_workbook("melos-final-ex2.xlsx", data_only=True)
# cust_df, dc_df, plnt_df, prod_df, demand_df, production_df = prepare_df_for_melos(wb)ルートデータフレームの生成と描画用のグラフの準備 prepare_trans_df
引数: - wb: データ入力済みExcel Workbook(輸配送ルートシートを含むものとする) - plnt_df : 工場データフレーム - dc_df : 倉庫データフレーム - cust_df : 顧客データフレーム
返値:
- trans_df : 輸配送ネットワークのデータフレーム
- graph : networkXのグラフインスタンス
- position : networkXの点の位置(経度、緯度のタプル)
点を表す辞書のキーに対しては、同名の工場,倉庫,顧客がある場合にエラーするので, 工場は “Plnt_”、倉庫は “DC_”、顧客は “Cust_”を先頭に負荷して区別するものとする。
prepare_trans_df
prepare_trans_df (wb, plnt_df, dc_df, cust_df)
prepare_trans_dfの使用例
# wb = load_workbook("melos-ex1-result.xlsx", data_only=True)
# cust_df, dc_df, plnt_df, prod_df, demand_df, production_df = prepare_df_for_melos(wb)
# trans_df, graph, position = prepare_trans_df(wb, plnt_df, dc_df, cust_df)顧客の集約を行う関数 customer_aggregation
顧客数が多い場合には,道路距離をもとに集約する.集約した顧客と需要データは,集約顧客シートに書き出す.
引数: - wb: データ入力済みExcel Workbook - cust_df : 顧客データフレーム - prod_df: 製品データフレーム - demand_df: 需要データフレーム - num_of_facilities: 集約後の顧客群数
返値:
- wb: 集約顧客シートを追加したExcel Workbook
- fig: 集約したネットワークの図
customer_aggregation
customer_aggregation (wb, cust_df, prod_df, demand_df, num_of_facilities)
customer_aggregation関数の使用例
# wb, fig = customer_aggregation(wb, cust_df, prod_df, demand_df, num_of_facilities=10)
# plotly.offline.plot(fig);
# #wb.save("melos-ex2-agg.xlsx")輸配送ネットワークシートを生成する関数 make_network_for_excel
顧客もしくは集約した顧客情報をもとに,ネットワークを構築する.
引数:
- wb: データ入力済みExcel Workbook
- cust_df : 顧客データフレーム
- dc_df : 倉庫データフレーム
- plnt_df : 工場データフレーム
- plnt_dc_threshold : 工場・倉庫間の距離の上限 (km)
- dc_cust_threshold : 倉庫・顧客間の距離の上限 (km)
- tc_per_dis : 工場・倉庫間の単位距離・重量あたりの輸送費用 (円/km/kg)
- dc_per_dis : 倉庫・顧客間の単位距離・重量あたりの配送費用 (円/km/kg)
- tc_per_time : 工場・倉庫間の単位時間・重量あたりの輸送費用 (円/h/kg)
- dc_per_time : 倉庫・顧客間の単位時間・重量あたりの配送費用 (円/h/kg)
- default_mult: 地点間に道路が存在しない場合に,移動距離を計算する際に,大圏距離に乗じる値
- default_velocity: 地点間に道路が存在しない場合の平均時速
返値: - wb: 輸配送ルートシートを追加したExcel Workbook - trans_df : 輸配送ネットワークのデータフレーム - graph : networkXのグラフインスタンス - position : networkXの点の位置(経度、緯度のタプル)
点を表す辞書のキーに対しては、同名の工場,倉庫,顧客がある場合にエラーするので, 工場は “Plnt_”、倉庫は “DC_”、顧客は “Cust_”を先頭に負荷して区別するものとする。
make_network_for_excel
make_network_for_excel (wb, cust_df, dc_df, plnt_df, plnt_dc_threshold=999999.0, dc_cust_threshold=999999.0, tc_per_dis=0.001, dc_per_dis=0.0025, tc_per_time=0.4, dc_per_time=2.0, default_mult=10.0, default_velocity=30.0)
make_network_for_excel関数の使用例
# wb = load_workbook("melos-ex1.xlsx", data_only=True)
# #wb = load_workbook("melos-ex2-agg.xlsx", data_only=True)
# cust_df, dc_df, plnt_df, prod_df, demand_df, production_df = prepare_df_for_melos(wb)
# plnt_dc_threshold = 20000 #999999.
# dc_cust_threshold = 1000 #999999.
# tc_per_dis = 20./20000
# dc_per_dis = 10./4000
# tc_per_time = 8000./20000
# dc_per_time = 8000./4000
# default_mult = 3. #大圏距離から道路距離を推定する際の倍率(迂回係数);離島に立地しないように大きめに設定しておく
# default_velocity = 30. #大圏距離の場合の平均時速
# # data = wb["集約顧客"].values
# # cols = next(data)[:]
# # data = list(data)
# # cust_df = pd.DataFrame(data, columns=cols).dropna(how="all")
# wb, trans_df , graph, position = make_network_for_excel(wb, cust_df, dc_df, plnt_df, plnt_dc_threshold, dc_cust_threshold,
# tc_per_dis, dc_per_dis, tc_per_time, dc_per_time, default_mult,default_velocity )
# trans_df.head()
# wb.save("melos-ex1-agg.xlsx")# fig = plot_scm(cust_df, dc_df, plnt_df, graph, position, node_only=False)
# plotly.offline.plot(fig);Excelファイルを読んで求解する関数 solve_lnd_for_excel
すべてのデータを入力したExcel Workbookとデータフレームをもとに,最適化を行う関数;結果はWorkbookに保存される.
引数: - wb: 結果を入れるためのExcel workbook - prod_df: 製品データフレーム - cust_df : 顧客データフレーム - dc_df : 倉庫データフレーム(固定費用、変動費用を追加) - plnt_df : 工場データフレーム - demand_df: 需要データフレーム - production_df: 生産データフレーム - trans_df: 輸配送データフレーム - dc_num: 開設したい倉庫数;下限と上限を指定したい場合にはタプル. 既定値は None で指定なし. - single_sourcing: 単一ソースの場合にTrue、それ以外のときFalse - max_cpu: 計算時間上限 - aggregation: 集約した顧客に対して最適化を行う場合True - fix_y: 倉庫の固定のための辞書;倉庫の番号をキー,固定したい数値(0か1)を値とする. - dc_slack_penalty: 倉庫の下限量逸脱のペナルティ;既定値は10000. - demand_slack_penalty: 需要を満たせない場合のペナルティ;既定値は10000000.
返値:
- flow_df: 輸・配送量が正の経路を入れたデータフレーム
- dc_df: 倉庫の開設の有無を表す列 (open_close) を追加した倉庫データフレーム
- cost_df: 費用の内訳を入れたデータフレーム
- violation_df: 制約の逸脱量を入れたデータフレーム
- Status: 最適化の状態(2でない場合は最適でない)
solve_lnd_for_excel
solve_lnd_for_excel (wb, prod_df, cust_df, dc_df, plnt_df, demand_df, production_df, trans_df, dc_num=None, single_sourcing=True, max_cpu=100, aggregation=False, fix_y=None, dc_slack_penalty=10000.0, demand_slack_penalty=10000000.0)
solve_lnd_for_excel関数の使用例
# wb = load_workbook("melos-ex1-agg.xlsx", data_only=True)
# cust_df, dc_df, plnt_df, prod_df, demand_df, production_df = prepare_df_for_melos(wb)
# trans_df, graph, position = prepare_trans_df(wb, plnt_df, dc_df, cust_df)
# #倉庫固定
# wb_out = load_workbook("melos-result.xlsx", data_only=True)
# fix_y = extract_fix_dc_info(wb_out)
# #求解
# flow_df, dc_df, cost_df, violation_df, model_status = solve_lnd_for_excel(wb, prod_df, cust_df, dc_df, plnt_df,
# demand_df, production_df, trans_df, dc_num=None, single_sourcing=False, max_cpu = 100,
# aggregation = False, fix_y=fix_y)
# fig = show_optimized_network(cust_df, dc_df, plnt_df, prod_df, flow_df, position)
# plotly.offline.plot(fig);求解結果をシートに追加する関数 add_result_for_melos
引数: - wb: 結果を入れるためのExcel workbook - flow_df: 輸・配送量が正の経路を入れたデータフレーム - cost_df: 費用の内訳を入れたデータフレーム - violation_df: 制約の逸脱量を入れたデータフレーム - dc_df: 倉庫の開設の有無を表す列 (open_close) を追加した倉庫データフレーム
返値: - wb: 費用内訳,制約逸脱,最適流量を追加したExcel workbook;倉庫シートには下限逸脱量と開設の列を追加
add_result_for_melos
add_result_for_melos (wb, flow_df, cost_df, violation_df, dc_df)
add_result_for_melos関数の使用例
# wb = add_result_for_melos(wb, flow_df, cost_df, violation_df, dc_df)
# wb.save("melos-result.xlsx")最適化結果Workbookの色情報を元に変数の固定情報を抽出する関数 extract_fix_dc_info
結果のWorkbookの倉庫候補地点シートの開設列に何らかの色を付けることによって,変数の固定を行う.
引数: - 最適化結果を入れたExcel Workbook
返値: - 倉庫の開設変数を固定する情報を含んだ辞書; 倉庫の番号をキー,固定したい数値(0か1)を値とする.
extract_fix_dc_info
extract_fix_dc_info (wb)
extract_fix_dc_info関数の使用例
# wb = load_workbook("melos-result.xlsx", data_only=True)
# #wb = load_workbook("melos-ex1.xlsx", data_only=True)
# fix_y = extract_fix_dc_info(wb)
# fix_yネットワーク設計モデルの結果をもとに配送最適化モデルを構築する関数 make_vrp
ネットワーク設計モデルの結果をもとに配送最適化モデルを構築する.
開設した倉庫ごとに,そこに割り当てられた顧客の集合 assigned_customers を保持する.
Excelファイルをもとに作成する. 結果のExcelファイル,集約の有無をもとに,配送最適化のジョブデータを生成する.工場からの輸送も同様に生成できる. 重量・容量の両者を考慮.
make_vrp
make_vrp (cust_df, aggregated_cust_df, aggregated_dc_df, aggregated_flow_df, agg_df_cust)
ネットワーク設計モデルの結果をもとに配送最適化モデルを構築する関数
集約された顧客(クラスター)に対する製品ごとの需要データを作成する関数 aggregate_demand_by_cluster
aggregated_cust_dfから作成する.
これを用いて,クラスタリングと集約されたデータに対するロジスティクス・ネットワーク設計モデルの橋渡しをする.
aggregate_demand_by_cluster
aggregate_demand_by_cluster (cust_df, aggregated_cust_df, demand_df)
集約された顧客(クラスター)に対する需要データを作成する関数
抽象ロジスティクス・オブジェクトを用いたロジスティクス・ネットワーク設計モデル
注:区分的線形関数をSOSで解くのでGurobiのみ
集合:
\(N\): 点の集合.原料供給地点,工場,倉庫の配置可能地点,顧客群の集合などのすべての地点を総称して点とよぶ.
\(A\): 枝の集合. 少なくとも1つの製品が移動する可能性のある点の対を枝とよぶ.
\(Prod\): 製品の集合. 製品は,ロジスティクス・ネットワーク内を流れる「もの」の総称である.
以下に定義する \(Child_p\), \(Parent_p\) は,製品の集合の部分集合である.
\(Child_p\): 部品展開表における製品 \(p\) の子製品の集合.言い換えれば,製品 \(p\) を製造するために必要な製品の集合.
\(Parent_p\): 部品展開表における製品 \(p\) の親製品の集合.言い換えれば,製品 \(p\) を分解することによって生成される製品の集合.
\(Res\): 資源の集合. 製品を処理(移動,組み立て,分解)するための資源の総称. 基本モデルでは枝上で定義される. たとえば,工場を表す枝における生産ライン(もしくは機械)や 輸送を表す枝における輸送機器(トラック,船,鉄道,飛行機など)が資源の代表的な要素となる.
\(NodeProd\): 需要もしくは供給が発生する点と製品の \(2\)つ組の集合.
\(ArcRes\): 枝と資源の可能な \(2\)つ組の集合. 枝 \(a \in A\) 上で資源 \(r \in Res\) が利用可能なとき,\((a,r)\) の組が 集合 \(ArcRes\) に含まれるものとする.
\(ArcResProd\): 枝と資源と製品の可能な \(3\)つ組の集合. 枝 \(a \in A\) 上の資源 \(r \in Res\) で製品 \(p \in Prod\) の処理が利用可能なとき, \((a,r,p)\) の組が 集合 \(ArcResProd\) に含まれるものとする.
以下に定義する \(Assemble\),\(Disassemble\) および \(Transit\) は \(ArcResProd\) の部分集合である.
\(Assemble\): 組み立てを表す枝と資源と製品の可能な \(3\) つ組の集合. 枝 \(a \in A\) 上の資源 \(r \in Res\) で製品 \(p \in Prod\) の組み立て処理が利用可能なとき,\((a,r,p)\) の組が 集合 \(Assemble\) に含まれるものとする.ここで製品 \(p\) の組み立て処理とは,子製品の集合 \(Child_p\) を用いて \(p\) を 製造することを指す.
\(Disassemble\): 分解を表す枝と資源と製品の可能な \(3\) つ組の集合. 枝 \(a \in A\) 上の資源 \(r \in Res\) で製品 \(p \in Prod\) の分解処理が利用可能なとき,\((a,r,p)\) の組が 集合 \(Disassemble\) に含まれるものとする.ここで製品 \(p\) の分解処理とは,\(p\) から親製品の集合 \(Parent_p\) を 生成することを指す.
\(Transit\): 移動を表す枝と資源と製品の可能な \(3\) つ組の集合. 枝 \(a \in A\) 上の資源 \(r \in Res\) で製品 \(p \in Prod\) が形態を変えずに流れることが可能なとき, \((a,r,p)\) の組は集合 \(Transit\) に含まれるものとする.
\(ResProd\): 資源と製品の可能な \(2\) つ組の集合. 集合 \(ArcResProd\) から生成される.
\(ArcProd\): 枝と製品の可能な \(2\) つ組の集合. 集合 \(ArcResProd\) から生成される.
入力データ:
\(D_i^p\): 点 \(i\) における製品 \(p\) の需要量(\(p\)-units \(/\) 単位期間); 負の需要は供給量を表す.ここで,\(p\)-unit とは,製品 \(p\) の \(1\) 単位を表す.
\(DPENALTY_{ip}^{+}\): 点 \(i\) における製品 \(p\) の \(1\) 単位あたりの需要超過(供給余裕)ペナルティ (円 \(/\) 単位期間・\(p\)-unit);通常は小さな値
\(DPENALTY_{ip}^{-}\): 点 \(i\) における製品 \(p\) の \(1\) 単位あたりの需要不足(供給超過)ペナルティ (円 \(/\) 単位期間・\(p\)-unit); 通常は大きな値
\(AFC_{ij}\): 枝 \((i,j)\) を使用するときに発生する固定費用(円 \(/\) 単位期間)
\(ARFC_{ijr}:\) 枝 \((i,j)\) 上で資源 \(r\) を使用するときに発生する固定費用(円 \(/\) 単位期間)
\(ARPVC_{ijr}^p\): 枝 \((i,j)\) 上で資源 \(r\) を利用して製品 \(p\) を \(1\) 単位処理するごとに発生する変動費用 (円 \(/\) 単位期間・\(p\)-unit)
\(\phi_{pq}\) : \(q \in Parent_p\) のとき, 品目 \(q\) を \(1\) 単位生成するのに必要な品目 \(p\) の数 (\(p\)-units); ここで, \(p\)-unitsとは,品目 \(q\) の \(1\)単位と混同しないために導入された単位であり, 品目 \(p\) の \(1\)単位を表す.\(\phi_{pq}\) は,部品展開表を有向グラフ表現したときには,枝の重みを表す. この値から以下の\(U_{p q}\)と\(\bar{U}_{p q}\)を計算する.
\(U_{p q}\): 製品 \(p\) の \(1\) 単位を組み立て処理するために必要な製品 \(q \in Child_p\) の量(\(q\)-units)
\(\bar{U}_{p q}\): 製品 \(p\) の \(1\) 単位を分解処理して生成される製品 \(q \in Parent_p\) の量(\(q\)-units)
\(RUB_r\): 資源 \(r\) の利用可能量上限(\(r\)-units)
\(R_{r}^{p}\): 製品 \(p\) の \(1\) 単位を(組み立て,分解,移動)処理する際に必要な資源 \(r\) の量(\(r\)-units); ここで,\(r\)-unit とは,資源 \(r\) の \(1\) 単位を表す.
\(CT_{ijr}^p\): 枝 \((i,j)\) 上で資源 \(r\) を利用して製品 \(p\) を処理する際のサイクル時間(単位期間)
\(LT_{ijr}^p\): 枝 \((i,j)\) 上で資源 \(r\) を利用して製品 \(p\) を処理する際のリード時間(単位期間)
\(VAL_{i}^p\): 点 \(i\) 上での製品 \(p\) の価値(円)
\(SSR_i^p\): 点 \(i\) 上での製品 \(p\) の安全在庫係数.(無次元)
\(VAR_p\): 製品 \(p\) の変動比率(\(p\)-units);これは,製品ごとの需要の分散と平均の比が一定と仮定したとき, 「需要の分散 \(/\) 需要の平均」と定義される値である.
\(ratio\): 利子率(% \(/\) 単位期間)
\(EIC_{ij}^p\): 枝 \((i,j)\) 上で資源 \(r\) を用いて処理(組み立て,分解,輸送)される 製品 \(p\) に対して定義されるエシェロン在庫費用(円 \(/\)単位期間); この値は,以下のように計算される. \[ EIC_{ijr}^p =\max\{ ratio \times \left(VAL_{j}^p- \sum_{q \in Child_p} \phi_{qp} VAL_{i}^q \right)/ 100, 0 \} \ \ \ (i,j,r,p) \in Assemble \] \[ EIC_{ijr}^p =\max\{ ratio \times \left(\sum_{q \in Parent_p} \phi_{pq} VAL_{j}^q -VAL_{i}^p \right)/ 100, 0 \} \ \ \ (i,j,r,p) \in Disassemble \] \[ EIC_{ijr}^p =\max\{ ratio \times \left(VAL_{j}^p -VAL_{i}^p\right)/ 100, 0 \} \ \ \ (i,j,r,p) \in Transit \]
\(CFP_{ijr}\): 枝 \((i,j)\) で資源 \(r\) を使用したときの\(CO_2\)排出量 (g); 輸送の場合には,資源 \(r\) の排出原単位 (g/km) に,枝 \((i,j)\) の距離 (km) を乗 じて計算しておく.
\(CFPV_{ijr}\): 資源 \(r\) の使用量(輸送の場合には積載重量)あたりの\(CO_2\)排出原単位(g \(/\) \(r\)-units)
\(CFPUB\): \(CO_2\)排出量上限(g)
変数は実数変数と\(0\)-\(1\)整数変数を用いる.
まず,実数変数を以下に示す.
\(w_{ijr}^p (\geq 0)\): 枝 \((i,j)\) で資源 \(r\) を利用して製品 \(p\) を処理する量を表す実数変数(\(p\)-units \(/\) 単位期間)
\(v_{ip}^+ (\geq 0)\): 点 \(i\) における製品 \(p\) の需要の超過量(需要が負のときには供給の超過量) を表す実数変数(\(p\)-units \(/\) 単位期間)
\(v_{ip}^- (\geq 0)\): 点 \(i\) における製品 \(p\) の需要の不足量(需要が負のときには供給の不足量) を表す実数変数(\(p\)-units \(/\) 単位期間)
\(0\)-\(1\)整数変数は,枝および枝上の資源の利用の有無を表現する.
- \(y_{ij} (\in \{0,1\})\): 枝\((i,j)\) を利用するとき \(1\),それ以外のとき \(0\)
- \(z_{ijr} (\in \{0,1\})\): 枝\((i,j)\) 上で資源 \(r\) を利用するとき \(1\),それ以外のとき \(0\)
定式化:
\[\begin{eqnarray*} \mbox{最小化} & \mbox{枝固定費用}+\mbox{枝・資源固定費用} + \\ & \mbox{枝・資源・製品変動費用}+ \mbox{供給量超過費用}+ \\ & \mbox{供給量不足費用}+ \mbox{需要量超過費用}+\mbox{需要量不足費用}+ \\ & \mbox{サイクル在庫費用} +\mbox{安全在庫費用}+\mbox{需要逸脱ペナルティ} \\ \mbox{条件} & \mbox{フロー整合条件} \\ & \mbox{資源使用量上限} \\ & \mbox{枝と枝上の資源の繋ぎ条件} \\ & \mbox{$CO_2$排出量上限制約} \end{eqnarray*}\]
- 目的関数の構成要素 \[ \mbox{枝固定費用} = \sum_{(i,j) \in A} AFC_{ij} y_{ij} \] \[ \mbox{枝・資源固定費用} = \sum_{(i,j,r) \in ArcRes} ARFC_{ijr} z_{ijr} \]
\[ \mbox{枝・資源・製品変動費用}= \sum_{(i,j,r,p) \in ArcResProd} ARPVC_{ijr}^p w_{ijr}^p \]
\[ \mbox{需要量超過費用}= \sum_{(i,p) \in NodeProd %: D_{i}^{p}>0 } DPENALTY_{ip}^+ v_{ip}^+ \] \[ \mbox{需要量不足費用}= \sum_{(i,p) \in NodeProd %: D_{i}^{p}>0 } DPENALTY_{ip}^- v_{ip}^- \] \[ \mbox{サイクル在庫費用} = \sum_{(i,j,r,p) \in ArcResProd} \frac{EIC_{ijr}^p CT_{ijr}^p }{2} w_{ijr}^p \] \[ \mbox{安全在庫費用} = \sum_{(i,j,r,p) \in ArcResProd} ratio \times VAL_j^p SSR_i^p \sqrt{VAR_p LT_{ijr}^p w_{ijr}^p} \] 上式における平方根は区分的線形関数で近似するものとする. \[ \mbox{需要逸脱ペナルティ} = \sum_{(i,p) \in NodeProd} DPENALTY_{ip}^{+} v_{ip}^+ + DPENALTY_{ip}^{-} v_{ip}^- \]
一般化フロー整合条件 \[ \sum_{r \in Res, j \in N: (j,i,r,p) \in Transit \cup Assemble} w_{jir}^p+ \sum_{r \in Res, j \in N: (j,i,r,q) \in Disassemble, p \in Parent_q} \phi_{qp} w_{jir}^q \\ = \sum_{r \in Res, k \in N: (i,k,r,p) \in Transit \cup Disassemble} w_{ikr}^p+ \sum_{r \in Res, k \in N: (i,k,r,q) \in Assemble, p \in Child_q} \phi_{pq} w_{ikr}^q+ \\ (\mbox{ if } (i,p) \in NodeProd \mbox{ then } D_i^p -v_{ip}^{-} +v_{ip}^{+} \mbox{ else } 0) \ \ \ \forall i \in N, p \in Prod \]
資源使用量上限 \[ \sum_{p \in Prod: (i,j,r,p) \in ArcResProd} R_{r}^p w_{ijr}^p \leq RUB_{r} z_{ijr} \ \ \ \forall (i,j,r) \in ArcRes \]
枝と枝上の資源の繋ぎ条件 \[ z_{ijr} \leq y_{ij} \ \ \ \forall (i,j,r) \in ArcRes \]
\(CO_2\)排出量上限制約
\[ \sum_{(i,j,r) \in ArcRes} CFP_{ijr} z_{ijr} + \sum_{ (i,j,r,p) \in ArcResProd} CFPV_{ijr} R_r^p w_{ijr}^p \leq CFPUB \]
抽象ロジスティクス・ネットワーク設計モデルを解く関数 LNDP
引数:
- Node: list of nodes
- ArcData: fixed cost (ArcFC) and Diatance (km)
- ProdData: weight (ton), variability of product (VAR)= variance/mean
- ResourceData: corbon foot print (CFP) data (kg/km), variable term of corbon foot print (VFPV) (kg/ton km)
- ResourceProdData: resource usage
- ArcResourceData: fixed cost (ArcResourceFC)
- ArcResourceProdData: type: 0=transport, 1=assemble, 2=dis-assemble, variable cost, cycle time, lead time (LT), and upper bound of flow volume (UB)
- NodeProdData: value, demand (negative values are supply), DPENALTY+, DPENALTY- (demand violation penalties)
- phi: BOM
返値: - model: __data に w,y,z,TotalArcFC,TotalArcResourceFC,TotalVC,TotalCycleIC,TotalSafetyIC を保持
LNDP
LNDP (Node, ArcData, ProdData, ResourceData, ResourceProdData, ArcResourceData, ArcResourceProdData, NodeProdData, phi)
convex_comb_sos
convex_comb_sos (model, a, b)
convex_comb_sos – add piecewise relation with gurobi’s SOS constraints Parameters: - model: a model where to include the piecewise linear relation - a[k]: x-coordinate of the k-th point in the piecewise linear relation - b[k]: y-coordinate of the k-th point in the piecewise linear relation Returns the model with the piecewise linear relation on added variables x, f, and z.
LNDPの使用例
#Node list
Node=[ "source1", "source2", "plantin", "plantout", "customer", "sink" ]
#Arc list, fixed cost (ArcFC) and Diatance (km)
ArcData={("source1", "plantin"): [100,200],
("source2", "plantin"): [100,500],
("plantin", "plantout"): [100,0],
("plantout", "customer"): [100,20],
("customer", "plantout") : [100,20],
("plantout", "plantin") : [100,0],
("plantin", "sink") : [100,300]
}
#Prod data
#weight (ton), variability of product (VAR)= variance/mean
ProdData={
"apple": [0.01,0],
"melon": [0.012,0],
"bottle":[0.03,0],
"juice1":[0.05,2],
"juice2":[0.055,3],
"retbottle":[0.03,5],
"glass":[0.01,0]
}
#resource list, fixed cost, upper bound
#corbon foot print (CFP) data (kg/km), variable term of corbon foot print (CFPV) (kg/ton km)
ResourceData={
"line1": [100,100,0, 0],
"line2": [20,100,0, 0],
"line3": [10,100,0, 0],
"vehicle": [100,100,0.8, 0.1],
"ship": [30,180, 0.2, 0.1]
}
#Resource-Prod data (resource usage)
ResourceProdData = {
("line1", "juice1"): 1,
("line2", "juice1"): 1,
("line1", "juice2"): 1,
("line2", "juice2"): 1,
("vehicle", "juice1"): 1,
("ship", "juice1"): 1,
("vehicle", "juice2"): 1,
("ship", "juice2"): 1,
("vehicle", "apple"): 1,
("vehicle", "melon"): 1,
("ship", "bottle"): 1,
("line3", "retbottle"): 1,
("vehicle", "retbottle"): 1,
("ship", "retbottle"): 1,
("ship", "glass"): 1,
}
#ArcResource list, fixed cost (ArcResourceFC)
ArcResourceData={
("source1", "plantin","vehicle"): 10,
("source2", "plantin","ship"): 30,
("plantin", "plantout","line1"): 50,
("plantin", "plantout","line2"): 100,
("plantout", "customer","vehicle"): 20,
("plantout", "customer","ship"): 40,
("customer", "plantout","vehicle"): 20,
("customer", "plantout","ship"): 40,
("plantout", "plantin","line3"): 80,
("plantin", "sink","ship"): 0
}
#ArcResourceProd data,
# type: 0=transport, 1=assemble, 2=dis-assemble,
# variable cost, cycle time, lead time (LT), and upper bound of flow volume (UB)
ArcResourceProdData= {
("source1", "plantin","vehicle","apple"): [0,1,1,10,50],
("source1", "plantin","vehicle","melon"): [0,2,2,20,50],
("source2", "plantin","ship","bottle"): [0,3,3,15,50],
("plantin", "plantout","line1","juice1"): [1,10,5,1,10],
("plantin", "plantout","line1","juice2"): [1,10,5,1,10],
("plantin", "plantout","line2","juice1"): [1,5,3,1,10],
("plantin", "plantout","line2","juice2"): [1,5,3,1,10],
("plantout", "customer","vehicle","juice1"): [0,10,5,3,10],
("plantout", "customer","vehicle","juice2"): [0,10,5,4,10],
("plantout", "customer","ship","juice1"): [0,2,2,10,10],
("plantout", "customer","ship","juice2"): [0,2,2,12,10],
("customer", "plantout","vehicle","retbottle"): [0,2,4,5,10],
("customer", "plantout","ship","retbottle"): [0,2,8,14,10],
("plantout", "plantin","line3","retbottle"): [2,5,2,1,10],
("plantin", "sink","ship","glass"): [0,1,8,20,10]
}
#Node-Prod data; value, demand (negative values are supply), DPENALTY+, DPENALTY- (demand violation penalties)
NodeProdData ={
("source1", "apple"): [10,-100,0,10000],
("source1", "melon"): [10,-50,0,10000],
("source2", "bottle"): [5,-100,0,10000],
("plantin", "apple"): [15,0,0,0],
("plantin", "melon"): [15,0,0,0],
("plantin", "bottle"): [8,0,0,0],
("plantout", "juice1"): [150,0,0,0],
("plantout", "juice2"): [160,0,0,0],
("customer", "juice1"): [170,10,0,10000],
("customer", "juice2"): [180,10,0,10000],
("customer", "retbottle"): [1,-10,10000,10000],
("plantout", "retbottle") : [2,0,0,0],
("plantin", "retbottle") : [9,0,0,0],
("plantin", "glass") : [1,0,0,0],
("sink", "glass") : [3,10,10000,0]
}
#BOM
Unit = {
("juice1", "apple"): 2,
("juice1", "melon"): 1,
("juice1", "bottle"): 1,
("juice2", "apple"): 2,
("juice2", "melon"): 2,
("juice2", "bottle"): 1
}
RevUnit ={
("retbottle", "bottle"): 0.9,
("retbottle", "glass"): 0.5
}
phi = {}
for (q,p) in Unit:
phi[p,q] = Unit[q,p]
for (p,q) in RevUnit:
phi[p,q] = RevUnit[p,q]
ratio = 5.0 #interest ratio
SSR=1.65 #safety stock ratio
CFPUB =400.0 #upper bound of carbon foot print (kg)
# model=LNDP(Node,ArcData,ProdData,ResourceData,ResourceProdData,ArcResourceData, ArcResourceProdData,NodeProdData,phi)
# w,y,z,TotalArcFC,TotalArcResourceFC,TotalVC,TotalCycleIC,TotalSafetyIC,TotalPenalty=model.__dataWarning: variable name "Arc fixed cost" has a space
Warning: constraint name "Corbon Foot Print Upper Bound" has a space
Warning: to let Gurobi read it back, use rlp format
Gurobi Optimizer version 9.5.0 build v9.5.0rc5 (mac64[x86])
Thread count: 8 physical cores, 16 logical processors, using up to 16 threads
Optimize a model with 86 rows, 352 columns and 885 nonzeros
Model fingerprint: 0x7acc7b34
Model has 15 SOS constraints
Variable types: 335 continuous, 17 integer (17 binary)
Coefficient statistics:
Matrix range [6e-02, 1e+04]
Objective range [1e+00, 1e+00]
Bounds range [1e+00, 5e+01]
RHS range [1e+00, 4e+02]
Presolve removed 32 rows and 39 columns
Presolve time: 0.00s
Presolved: 54 rows, 313 columns, 655 nonzeros
Presolved model has 15 SOS constraint(s)
Variable types: 300 continuous, 13 integer (13 binary)
Found heuristic solution: objective 300000.00000
Root relaxation: objective 1.906563e+03, 36 iterations, 0.00 seconds (0.00 work units)
Nodes | Current Node | Objective Bounds | Work
Expl Unexpl | Obj Depth IntInf | Incumbent BestBd Gap | It/Node Time
0 0 1975.96529 0 10 300000.000 1975.96529 99.3% - 0s
H 0 0 111357.35195 1975.96529 98.2% - 0s
0 0 2087.38699 0 4 111357.352 2087.38699 98.1% - 0s
H 0 0 2087.3869894 2087.38699 0.00% - 0s
0 0 2087.38699 0 4 2087.38699 2087.38699 0.00% - 0s
Cutting planes:
Gomory: 1
Implied bound: 5
Relax-and-lift: 6
Explored 1 nodes (46 simplex iterations) in 0.04 seconds (0.02 work units)
Thread count was 16 (of 16 available processors)
Solution count 3: 2087.39 111357 300000
Optimal solution found (tolerance 1.00e-04)
Best objective 2.087386989394e+03, best bound 2.087386989394e+03, gap 0.0000%
Opt.value= 2087.386989393903
Total Arc Fixed Cost 700.0
Total Arc Resource Fixed Cost 260.0
Total Variable Cost 508.0
Total Cycle Inventory Cost 212.575
Total Safety Inventory Cost 406.81198939390316
Arc
y(source1,plantin) Fixed Cost = 100
y(source2,plantin) Fixed Cost = 100
y(plantin,plantout) Fixed Cost = 100
y(plantout,customer) Fixed Cost = 100
y(customer,plantout) Fixed Cost = 100
y(plantout,plantin) Fixed Cost = 100
y(plantin,sink) Fixed Cost = 100
Arc Resource
z(source1,plantin,vehicle) = 1.0 Fixed Cost = 10.0
z(source2,plantin,ship) = 1.0 Fixed Cost = 30.0
z(plantin,plantout,line2) = 1.0 Fixed Cost = 100.0
z(plantout,customer,vehicle) = 1.0 Fixed Cost = 20.0
z(customer,plantout,vehicle) = 1.0 Fixed Cost = 20.0
z(plantout,plantin,line3) = 1.0 Fixed Cost = 80.0
z(plantin,sink,ship) = 1.0 Fixed Cost = 0.0
Arc Resource Prod
w(source1,plantin,vehicle,apple) = 40.0 Var. Cost = 40.0 Cycle IC = 5.0 Safety IC = 0.0
w(source1,plantin,vehicle,melon) = 30.0 Var. Cost = 60.0 Cycle IC = 7.5 Safety IC = 0.0
w(source2,plantin,ship,bottle) = 11.0 Var. Cost = 33.0 Cycle IC = 2.4749999999999996 Safety IC = 0.0
w(plantin,plantout,line2,juice1) = 10.0 Var. Cost = 50.0 Cycle IC = 72.75 Safety IC = 55.3426824431198
w(plantin,plantout,line2,juice2) = 10.0 Var. Cost = 50.0 Cycle IC = 69.0 Safety IC = 72.29937759068193
w(plantout,customer,vehicle,juice1) = 10.0 Var. Cost = 100.0 Cycle IC = 25.0 Safety IC = 108.63718286111803
w(plantout,customer,vehicle,juice2) = 10.0 Var. Cost = 100.0 Cycle IC = 25.0 Safety IC = 162.67359957903435
w(customer,plantout,vehicle,retbottle) = 10.0 Var. Cost = 20.0 Cycle IC = 1.0 Safety IC = 2.608879069638913
w(plantout,plantin,line3,retbottle) = 10.0 Var. Cost = 50.0 Cycle IC = 2.8499999999999996 Safety IC = 5.250267850310115
w(plantin,sink,ship,glass) = 5.0 Var. Cost = 5.0 Cycle IC = 2.0 Safety IC = 0.0
Corbon Foot Print Usage 352.0
Total Violation Penalty 0.0
v_plus(source1,apple)= 60.0
v_plus(source1,melon)= 20.0
v_plus(source2,bottle)= 89.0
v_minus(sink,glass)= 5.0クラスによるLNDPの表現
- 点クラス
- 枝クラス
- 製品クラス
- 資源クラス
温室化ガス排出量
生産部門では,電力,蒸気に対して原単位が設定されている.
廃棄に対しても,物別に原単位が設定されている.
調達に対しては,調達費用に対して原単位が設定されている.
輸送部門:
| 輸送手段 | \(CO_2\) (gCO2/トンキロ) |
|---|---|
| 鉄道 | 22 |
| 船舶 | 39 |
| 航空 | 1490 |
トラックに対しては,燃料使用量を以下の式で計算してから算出する.
- y:輸送トンキロ当たり燃料使用量(l)
- x:積載率(%)
- z:最大積載量(kg)
ガソリン車: ln y=2.67-0.927 ln (x/100)-0.648 ln z
ディーゼル車: ln y=2.71-0.812 ln (x/100)-0.654 ln z
ただし,積載率10%未満の場合は、積載率10%の時の値を用いる.なお、表記「ln」は自然対数(eを底とする対数)
\(CO_2\)排出量は,上で求めた燃料使用量に以下の値を乗じて計算する.
単位発熱量(GJ/kl)×排出係数(tCO2/GJ) = 34.6 × 0.0183 = 2.322 (tCO2/kl)
co2
co2 (capacity, rate=0.5, diesel=False)
引数: - capacity:積載重量(kg) - rate: 積載率 (0<rate<=1.0) - diesel: ディーゼル車の場合 True, ガソリン車の場合 False 返値: - fuel: トンキロあたりの燃料使用量(リットル) - co2: CO2排出量(g)
事例
Piecewise linear concave regression
\(K\) 個の単調非減少,連続,区分的線形な凹関数で近似する.
\[ f(x) = \min_{k=1,\ldots,K} \{ b_k + a_k x \} \]
我々が近似したいのは,単調非減少かつ連続かつ非負な凹関数であるので, 以下の制約を加える. \[ a_k \geq a_{k+1} (\geq 0) \ \ \ k=1,\ldots,K-1 \] \[ (0 \leq) b_k \leq b_{k+1} \ \ \ k=1,\ldots,K-1 \]
データ \(x^{(i)}, y^{(i)}, i=1,\ldots,m\) が与えられたときに,以下の絶対値誤差を最小化する.
\[ \sum_{i} |y^{(i)} - f(x^{(i)})| \]
予測値は \(\hat{y}^{(i)} = f(x^{(i)}) = \min_{k=1,\ldots,K} \{ b_k + a_k x^{(i)} \}\) である.
\(K\) 個の線形関数の最小値が \(\hat{y}^{(i)}\) になるためには,\(0\)-\(1\) 変数 \(z_{k}^{(i)}\) が必要になる.
いずれかの線形関数が選択されるという条件 \[ \sum_{k} z_{k}^{(i)} = 1 \ \ \ i=1,\ldots,m \] のもとで,以下の制約を加える.
\[ \hat{y}^{(i)} \leq b_k + a_k x^{(i)} \ \ \ i=1,\ldots,m, k=1,\ldots,K \] \[ \hat{y}^{(i)} \geq b_k + a_k x^{(i)} - M (1-z_{k}^{(i)}) \ \ \ i=1,\ldots,m, k=1,\ldots,K \] ここで \(M\) は非常に大きな数とする.
目的関数は絶対値を表す変数 \(Y^{(i)}\) を用いて,以下のように書ける. \[ \sum_{i} Y^{(i)} \] \[ Y^{(i)} \geq y^{(i)} - \hat{y}^{(i)} \ \ \ i=1,\ldots,m \] \[ Y^{(i)} \geq -y^{(i)} + \hat{y}^{(i)} \ \ \ i=1,\ldots,m \]
# K = 3
# epsilon = 0.01
# M = 10000
# x = df_predict.weight
# y = df_predict.Label
# m = len(x)
# model = Model()
# a, b = {}, {}
# z, Y, yhat = {}, {}, {}
# for k in range(K):
# a[k] = model.addVar(vtype="C", name= f"a({k})") #非負を仮定
# b[k] = model.addVar(vtype="C", name= f"b({k})")
# for i in range(m):
# Y[i] = model.addVar(vtype="C", name= f"Y({i})")
# yhat[i] = model.addVar(vtype="C", name= f"yhat({i})")
# for k in range(K):
# z[i,k] = model.addVar(vtype="B", name= f"z({i,k})")
# model.update()# for k in range(K-1):
# model.addConstr(a[k]-epsilon >= a[k+1])
# model.addConstr(b[k]+epsilon <= b[k+1])
# for i in range(m):
# model.addConstr(quicksum(z[i,k] for k in range(K))==1) #SOS
# model.addSOS(GRB.SOS_TYPE1, [z[i,k] for k in range(K)] )
# for i in range(m):
# for k in range(K):
# model.addConstr( yhat[i]<= b[k]+x[i]*a[k] )
# model.addConstr( yhat[i]>= b[k]+x[i]*a[k]-M*(1-z[i,k]) )
# for i in range(m):
# model.addConstr(Y[i]>= y[i]-yhat[i])
# model.addConstr(Y[i]>= -y[i]+yhat[i])
# model.setObjective(quicksum(Y[i] for i in range(m)), GRB.MINIMIZE)# model.optimize()# for k in a:
# print(k,a[k].X, b[k].X)# yy =[]
# for i in yhat:
# #print(i,yhat[i].X)
# yy.append(yhat[i].X)
# df_predict["y_piecewise"] = yy
# fig = px.line(df_predict, x = "weight", y=["Label", "y_piecewise"])
# plotly.offline.plot(fig);